|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Loading...
Searching...
No Matches
|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Hierarchical Data Format version 5 interface. More...
#include <opencv2/hdf/hdf5.hpp>
Public Types | |
| enum | { H5_UNLIMITED = -1 , H5_NONE = -1 , H5_GETDIMS = 100 , H5_GETMAXDIMS = 101 , H5_GETCHUNKDIMS = 102 } |
Public Member Functions | |
| virtual | ~HDF5 () |
| virtual void | atdelete (const String &atlabel)=0 |
| virtual bool | atexists (const String &atlabel) const =0 |
| virtual void | atread (double *value, const String &atlabel)=0 |
| virtual void | atread (int *value, const String &atlabel)=0 |
| virtual void | atread (OutputArray value, const String &atlabel)=0 |
| virtual void | atread (String *value, const String &atlabel)=0 |
| virtual void | atwrite (const double value, const String &atlabel)=0 |
| virtual void | atwrite (const int value, const String &atlabel)=0 |
| virtual void | atwrite (const String &value, const String &atlabel)=0 |
| virtual void | atwrite (InputArray value, const String &atlabel)=0 |
| virtual void | close ()=0 |
| Close and release hdf5 object. | |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel) const =0 |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel, const int compresslevel) const =0 |
| virtual void | dscreate (const int n_dims, const int *sizes, const int type, const String &dslabel, const int compresslevel, const int *dims_chunks) const =0 |
| Create and allocate storage for n-dimensional dataset, single or multichannel type. | |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel) const =0 |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel) const =0 |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel, const int *dims_chunks) const =0 |
| Create and allocate storage for two dimensional single or multi channel dataset. | |
| virtual void | dscreate (const int rows, const int cols, const int type, const String &dslabel, const int compresslevel, const vector< int > &dims_chunks) const =0 |
| virtual void | dscreate (const vector< int > &sizes, const int type, const String &dslabel, const int compresslevel=HDF5::H5_NONE, const vector< int > &dims_chunks=vector< int >()) const =0 |
| virtual vector< int > | dsgetsize (const String &dslabel, int dims_flag=HDF5::H5_GETDIMS) const =0 |
| Fetch dataset sizes. | |
| virtual int | dsgettype (const String &dslabel) const =0 |
| Fetch dataset type. | |
| virtual void | dsinsert (InputArray Array, const String &dslabel) const =0 |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| Insert or overwrite a Mat object into specified dataset and auto expand dataset size if unlimited property allows. | |
| virtual void | dsinsert (InputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dsread (OutputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| Read specific dataset from hdf5 file into Mat object. | |
| virtual void | dsread (OutputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel, const int *dims_offset) const =0 |
| virtual void | dswrite (InputArray Array, const String &dslabel, const int *dims_offset, const int *dims_counts) const =0 |
| Write or overwrite a Mat object into specified dataset of hdf5 file. | |
| virtual void | dswrite (InputArray Array, const String &dslabel, const vector< int > &dims_offset, const vector< int > &dims_counts=vector< int >()) const =0 |
| virtual void | grcreate (const String &grlabel)=0 |
| Create a group. | |
| virtual bool | hlexists (const String &label) const =0 |
| Check if label exists or not. | |
| virtual void | kpcreate (const int size, const String &kplabel, const int compresslevel=H5_NONE, const int chunks=H5_NONE) const =0 |
| Create and allocate special storage for cv::KeyPoint dataset. | |
| virtual int | kpgetsize (const String &kplabel, int dims_flag=HDF5::H5_GETDIMS) const =0 |
| Fetch keypoint dataset size. | |
| virtual void | kpinsert (const vector< KeyPoint > keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| Insert or overwrite list of KeyPoint into specified dataset and autoexpand dataset size if unlimited property allows. | |
| virtual void | kpread (vector< KeyPoint > &keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| Read specific keypoint dataset from hdf5 file into vector<KeyPoint> object. | |
| virtual void | kpwrite (const vector< KeyPoint > keypoints, const String &kplabel, const int offset=H5_NONE, const int counts=H5_NONE) const =0 |
| Write or overwrite list of KeyPoint into specified dataset of hdf5 file. | |
Hierarchical Data Format version 5 interface.
Notice that this module is compiled only when hdf5 is correctly installed.
| anonymous enum |
| Enumerator | |
|---|---|
| H5_UNLIMITED | The dimension size is unlimited,.
|
| H5_NONE | No compression,.
|
| H5_GETDIMS | Get the dimension information of a dataset.
|
| H5_GETMAXDIMS | Get the maximum dimension information of a dataset.
|
| H5_GETCHUNKDIMS | Get the chunk sizes of a dataset.
|
|
inlinevirtual |
|
pure virtual |
Delete an attribute from the root group.
| atlabel | the attribute to be deleted. |
|
pure virtual |
|
pure virtual |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
Read an attribute from the root group.
| value | address where the attribute is read into |
| atlabel | attribute name |
The following example demonstrates how to read an attribute of type cv::String:
|
pure virtual |
Read an attribute from the root group.
| value | attribute value. Currently, only n-d continuous multi-channel arrays are supported. |
| atlabel | attribute name. |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
Write an attribute inside the root group.
| value | attribute value. |
| atlabel | attribute name. |
The following example demonstrates how to write an attribute of type cv::String:
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
Write an attribute into the root group.
| value | attribute value. Currently, only n-d continuous multi-channel arrays are supported. |
| atlabel | attribute name. |
|
pure virtual |
Close and release hdf5 object.
|
pure virtual |
|
pure virtual |
|
pure virtual |
Create and allocate storage for n-dimensional dataset, single or multichannel type.
| n_dims | declare number of dimensions |
| sizes | array containing sizes for each dimensions |
| type | type to be used, e.g., CV_8UC3, CV_32FC1, etc. |
| dslabel | specify the hdf5 dataset label. Existing dataset label will cause an error. |
| compresslevel | specify the compression level 0-9 to be used, H5_NONE is the default value and means no compression. The value 0 also means no compression. A value 9 indicating the best compression ration. Note that a higher compression level indicates a higher computational cost. It relies on GNU gzip for compression. |
| dims_chunks | each array member specifies chunking sizes to be used for block I/O, by default NULL means none at all. |
|
pure virtual |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
Create and allocate storage for two dimensional single or multi channel dataset.
| rows | declare amount of rows |
| cols | declare amount of columns |
| type | type to be used, e.g, CV_8UC3, CV_32FC1 and etc. |
| dslabel | specify the hdf5 dataset label. Existing dataset label will cause an error. |
| compresslevel | specify the compression level 0-9 to be used, H5_NONE is the default value and means no compression. The value 0 also means no compression. A value 9 indicating the best compression ration. Note that a higher compression level indicates a higher computational cost. It relies on GNU gzip for compression. |
| dims_chunks | each array member specifies the chunking size to be used for block I/O, by default NULL means none at all. |
|
pure virtual |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
pure virtual |
|
pure virtual |
Fetch dataset sizes.
| dslabel | specify the hdf5 dataset label to be measured. |
| dims_flag | will fetch dataset dimensions on H5_GETDIMS, dataset maximum dimensions on H5_GETMAXDIMS, and chunk sizes on H5_GETCHUNKDIMS. |
Returns vector object containing sizes of dataset on each dimensions.
|
pure virtual |
Fetch dataset type.
| dslabel | specify the hdf5 dataset label to be checked. |
Returns the stored matrix type. This is an identifier compatible with the CvMat type system, like e.g. CV_16SC5 (16-bit signed 5-channel array), and so on.
|
pure virtual |
|
pure virtual |
|
pure virtual |
Insert or overwrite a Mat object into specified dataset and auto expand dataset size if unlimited property allows.
| Array | specify Mat data array to be written. |
| dslabel | specify the target hdf5 dataset label. |
| dims_offset | each array member specify the offset location over dataset's each dimensions from where InputArray will be (over)written into dataset. |
| dims_counts | each array member specify the amount of data over dataset's each dimensions from InputArray that will be written into dataset. |
Writes Mat object into targeted dataset and autoexpand dataset dimension if allowed.
|
pure virtual |
|
pure virtual |
|
pure virtual |
|
pure virtual |
Read specific dataset from hdf5 file into Mat object.
| Array | Mat container where data reads will be returned. |
| dslabel | specify the source hdf5 dataset label. |
| dims_offset | each array member specify the offset location over each dimensions from where dataset starts to read into OutputArray. |
| dims_counts | each array member specify the amount over dataset's each dimensions of dataset to read into OutputArray. |
Reads out Mat object reflecting the stored dataset.
|
pure virtual |
|
pure virtual |
|
pure virtual |
|
pure virtual |
Write or overwrite a Mat object into specified dataset of hdf5 file.
| Array | specify Mat data array to be written. |
| dslabel | specify the target hdf5 dataset label. |
| dims_offset | each array member specify the offset location over dataset's each dimensions from where InputArray will be (over)written into dataset. |
| dims_counts | each array member specifies the amount of data over dataset's each dimensions from InputArray that will be written into dataset. |
Writes Mat object into targeted dataset.
|
pure virtual |
|
pure virtual |
Create a group.
| grlabel | specify the hdf5 group label. |
Create a hdf5 group with default properties. The group is closed automatically after creation.
In this example, Group1 will have one subgroup called SubGroup1:
The corresponding result visualized using the HDFView tool is
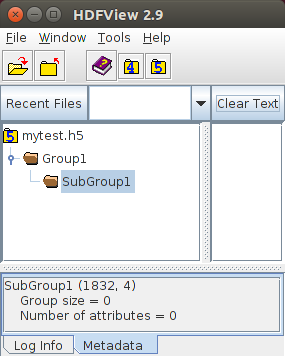
|
pure virtual |
Check if label exists or not.
| label | specify the hdf5 dataset label. |
Returns true if dataset exists, and false otherwise.
|
pure virtual |
Create and allocate special storage for cv::KeyPoint dataset.
| size | declare fixed number of KeyPoints |
| kplabel | specify the hdf5 dataset label, any existing dataset with the same label will be overwritten. |
| compresslevel | specify the compression level 0-9 to be used, H5_NONE is default and means no compression. |
| chunks | each array member specifies chunking sizes to be used for block I/O, H5_NONE is default and means no compression. |
|
pure virtual |
Fetch keypoint dataset size.
| kplabel | specify the hdf5 dataset label to be measured. |
| dims_flag | will fetch dataset dimensions on H5_GETDIMS, and dataset maximum dimensions on H5_GETMAXDIMS. |
Returns size of keypoints dataset.
|
pure virtual |
Insert or overwrite list of KeyPoint into specified dataset and autoexpand dataset size if unlimited property allows.
| keypoints | specify keypoints data list to be written. |
| kplabel | specify the target hdf5 dataset label. |
| offset | specify the offset location on dataset from where keypoints will be (over)written into dataset. |
| counts | specify the amount of keypoints that will be written into dataset. |
Writes vector<KeyPoint> object into targeted dataset and autoexpand dataset dimension if allowed.
|
pure virtual |
Read specific keypoint dataset from hdf5 file into vector<KeyPoint> object.
| keypoints | vector<KeyPoint> container where data reads will be returned. |
| kplabel | specify the source hdf5 dataset label. |
| offset | specify the offset location over dataset from where read starts. |
| counts | specify the amount of keypoints from dataset to read. |
Reads out vector<KeyPoint> object reflecting the stored dataset.
|
pure virtual |
Write or overwrite list of KeyPoint into specified dataset of hdf5 file.
| keypoints | specify keypoints data list to be written. |
| kplabel | specify the target hdf5 dataset label. |
| offset | specify the offset location on dataset from where keypoints will be (over)written into dataset. |
| counts | specify the amount of keypoints that will be written into dataset. |
Writes vector<KeyPoint> object into targeted dataset.