|
OpenCV 4.13.0-dev
Open Source Computer Vision
|
Loading...
Searching...
No Matches
|
OpenCV 4.13.0-dev
Open Source Computer Vision
|
Prev Tutorial: Introduction to Support Vector Machines
Next Tutorial: Introduction to Principal Component Analysis (PCA)
| Original author | Fernando Iglesias García |
| Compatibility | OpenCV >= 3.0 |
In this tutorial you will learn how to:
Why is it interesting to extend the SVM optimization problem in order to handle non-linearly separable training data? Most of the applications in which SVMs are used in computer vision require a more powerful tool than a simple linear classifier. This stems from the fact that in these tasks the training data can be rarely separated using an hyperplane.
Consider one of these tasks, for example, face detection. The training data in this case is composed by a set of images that are faces and another set of images that are non-faces (every other thing in the world except from faces). This training data is too complex so as to find a representation of each sample (feature vector) that could make the whole set of faces linearly separable from the whole set of non-faces.
Remember that using SVMs we obtain a separating hyperplane. Therefore, since the training data is now non-linearly separable, we must admit that the hyperplane found will misclassify some of the samples. This misclassification is a new variable in the optimization that must be taken into account. The new model has to include both the old requirement of finding the hyperplane that gives the biggest margin and the new one of generalizing the training data correctly by not allowing too many classification errors.
We start here from the formulation of the optimization problem of finding the hyperplane which maximizes the margin (this is explained in the previous tutorial (Introduction to Support Vector Machines):
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i\]
There are multiple ways in which this model can be modified so it takes into account the misclassification errors. For example, one could think of minimizing the same quantity plus a constant times the number of misclassification errors in the training data, i.e.:
\[\min ||\beta||^{2} + C \text{(misclassification errors)}\]
However, this one is not a very good solution since, among some other reasons, we do not distinguish between samples that are misclassified with a small distance to their appropriate decision region or samples that are not. Therefore, a better solution will take into account the distance of the misclassified samples to their correct decision regions, i.e.:
\[\min ||\beta||^{2} + C \text{(distance of misclassified samples to their correct regions)}\]
For each sample of the training data a new parameter \(\xi_{i}\) is defined. Each one of these parameters contains the distance from its corresponding training sample to their correct decision region. The following picture shows non-linearly separable training data from two classes, a separating hyperplane and the distances to their correct regions of the samples that are misclassified.
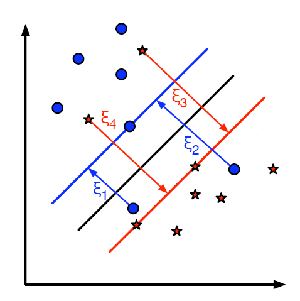
The red and blue lines that appear on the picture are the margins to each one of the decision regions. It is very important to realize that each of the \(\xi_{i}\) goes from a misclassified training sample to the margin of its appropriate region.
Finally, the new formulation for the optimization problem is:
\[\min_{\beta, \beta_{0}} L(\beta) = ||\beta||^{2} + C \sum_{i} {\xi_{i}} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 - \xi_{i} \text{ and } \xi_{i} \geq 0 \text{ } \forall i\]
How should the parameter C be chosen? It is obvious that the answer to this question depends on how the training data is distributed. Although there is no general answer, it is useful to take into account these rules:
You may also find the source code in samples/cpp/tutorial_code/ml/non_linear_svms folder of the OpenCV source library or download it from here.
The training data of this exercise is formed by a set of labeled 2D-points that belong to one of two different classes. To make the exercise more appealing, the training data is generated randomly using a uniform probability density functions (PDFs).
We have divided the generation of the training data into two main parts.
In the first part we generate data for both classes that is linearly separable.
In the second part we create data for both classes that is non-linearly separable, data that overlaps.
There are just two differences between the configuration we do here and the one that was done in the previous tutorial (Introduction to Support Vector Machines) that we use as reference.
C. We chose here a small value of this parameter in order not to punish too much the misclassification errors in the optimization. The idea of doing this stems from the will of obtaining a solution close to the one intuitively expected. However, we recommend to get a better insight of the problem by making adjustments to this parameter.
We call the method cv::ml::SVM::train to build the SVM model. Watch out that the training process may take a quite long time. Have patiance when your run the program.
The method cv::ml::SVM::predict is used to classify an input sample using a trained SVM. In this example we have used this method in order to color the space depending on the prediction done by the SVM. In other words, an image is traversed interpreting its pixels as points of the Cartesian plane. Each of the points is colored depending on the class predicted by the SVM; in dark green if it is the class with label 1 and in dark blue if it is the class with label 2.
The method cv::circle is used to show the samples that compose the training data. The samples of the class labeled with 1 are shown in light green and in light blue the samples of the class labeled with 2.
We use here a couple of methods to obtain information about the support vectors. The method cv::ml::SVM::getSupportVectors obtain all support vectors. We have used this methods here to find the training examples that are support vectors and highlight them.

You may observe a runtime instance of this on the YouTube here.