|
OpenCV
4.5.3
Open Source Computer Vision
|
|
OpenCV
4.5.3
Open Source Computer Vision
|
Classes | |
| struct | hashnode_i |
| struct | hashtable_int |
| class | cv::ppf_match_3d::ICP |
| This class implements a very efficient and robust variant of the iterative closest point (ICP) algorithm. The task is to register a 3D model (or point cloud) against a set of noisy target data. The variants are put together by myself after certain tests. The task is to be able to match partial, noisy point clouds in cluttered scenes, quickly. You will find that my emphasis is on the performance, while retaining the accuracy. This implementation is based on Tolga Birdal's MATLAB implementation in here: http://www.mathworks.com/matlabcentral/fileexchange/47152-icp-registration-using-efficient-variants-and-multi-resolution-scheme The main contributions come from: More... | |
| class | cv::ppf_match_3d::Pose3D |
| Class, allowing the storage of a pose. The data structure stores both the quaternions and the matrix forms. It supports IO functionality together with various helper methods to work with poses. More... | |
| class | cv::ppf_match_3d::PoseCluster3D |
| When multiple poses (see Pose3D) are grouped together (contribute to the same transformation) pose clusters occur. This class is a general container for such groups of poses. It is possible to store, load and perform IO on these poses. More... | |
| class | cv::ppf_match_3d::PPF3DDetector |
| Class, allowing the load and matching 3D models. Typical Use: More... | |
| struct | THash |
| Struct, holding a node in the hashtable. More... | |
Typedefs | |
| typedef uint | cv::ppf_match_3d::KeyType |
| typedef Ptr< Pose3D > | cv::ppf_match_3d::Pose3DPtr |
| typedef Ptr< PoseCluster3D > | cv::ppf_match_3d::PoseCluster3DPtr |
Functions | |
| Mat | cv::ppf_match_3d::addNoisePC (Mat pc, double scale) |
| void | cv::ppf_match_3d::computeBboxStd (Mat pc, Vec2f &xRange, Vec2f &yRange, Vec2f &zRange) |
| int | cv::ppf_match_3d::computeNormalsPC3d (const Mat &PC, Mat &PCNormals, const int NumNeighbors, const bool FlipViewpoint, const Vec3f &viewpoint) |
| Compute the normals of an arbitrary point cloud computeNormalsPC3d uses a plane fitting approach to smoothly compute local normals. Normals are obtained through the eigenvector of the covariance matrix, corresponding to the smallest eigen value. If PCNormals is provided to be an Nx6 matrix, then no new allocation is made, instead the existing memory is overwritten. More... | |
| void | cv::ppf_match_3d::destroyFlann (void *flannIndex) |
| void | cv::ppf_match_3d::getRandomPose (Matx44d &Pose) |
| hashtable_int * | cv::ppf_match_3d::hashtable_int_clone (hashtable_int *hashtbl) |
| hashtable_int * | cv::ppf_match_3d::hashtableCreate (size_t size, size_t(*hashfunc)(uint)) |
| void | cv::ppf_match_3d::hashtableDestroy (hashtable_int *hashtbl) |
| void * | cv::ppf_match_3d::hashtableGet (hashtable_int *hashtbl, KeyType key) |
| hashnode_i * | cv::ppf_match_3d::hashtableGetBucketHashed (hashtable_int *hashtbl, KeyType key) |
| int | cv::ppf_match_3d::hashtableInsert (hashtable_int *hashtbl, KeyType key, void *data) |
| int | cv::ppf_match_3d::hashtableInsertHashed (hashtable_int *hashtbl, KeyType key, void *data) |
| void | cv::ppf_match_3d::hashtablePrint (hashtable_int *hashtbl) |
| hashtable_int * | cv::ppf_match_3d::hashtableRead (FILE *f) |
| int | cv::ppf_match_3d::hashtableRemove (hashtable_int *hashtbl, KeyType key) |
| int | cv::ppf_match_3d::hashtableResize (hashtable_int *hashtbl, size_t size) |
| int | cv::ppf_match_3d::hashtableWrite (const hashtable_int *hashtbl, const size_t dataSize, FILE *f) |
| void * | cv::ppf_match_3d::indexPCFlann (Mat pc) |
| Mat | cv::ppf_match_3d::loadPLYSimple (const char *fileName, int withNormals=0) |
| Load a PLY file. More... | |
| static uint | cv::ppf_match_3d::next_power_of_two (uint value) |
| Round up to the next highest power of 2. More... | |
| Mat | cv::ppf_match_3d::normalizePCCoeff (Mat pc, float scale, float *Cx, float *Cy, float *Cz, float *MinVal, float *MaxVal) |
| void | cv::ppf_match_3d::queryPCFlann (void *flannIndex, Mat &pc, Mat &indices, Mat &distances) |
| void | cv::ppf_match_3d::queryPCFlann (void *flannIndex, Mat &pc, Mat &indices, Mat &distances, const int numNeighbors) |
| Mat | cv::ppf_match_3d::samplePCByQuantization (Mat pc, Vec2f &xrange, Vec2f &yrange, Vec2f &zrange, float sample_step_relative, int weightByCenter=0) |
| Mat | cv::ppf_match_3d::samplePCUniform (Mat PC, int sampleStep) |
| Mat | cv::ppf_match_3d::samplePCUniformInd (Mat PC, int sampleStep, std::vector< int > &indices) |
| Mat | cv::ppf_match_3d::transformPCPose (Mat pc, const Matx44d &Pose) |
| Mat | cv::ppf_match_3d::transPCCoeff (Mat pc, float scale, float Cx, float Cy, float Cz, float MinVal, float MaxVal) |
| void | cv::ppf_match_3d::writePLY (Mat PC, const char *fileName) |
| Write a point cloud to PLY file. More... | |
| void | cv::ppf_match_3d::writePLYVisibleNormals (Mat PC, const char *fileName) |
| Used for debbuging pruposes, writes a point cloud to a PLY file with the tip of the normal vectors as visible red points. More... | |
The following patents have been issued for methods embodied in this software: "Recognition and pose determination of 3D objects in 3D scenes using geometric point pair descriptors and the generalized Hough Transform", Bertram Heinrich Drost, Markus Ulrich, EP Patent 2385483 (Nov. 21, 2012), assignee: MVTec Software GmbH, 81675 Muenchen (Germany); "Recognition and pose determination of 3D objects in 3D scenes", Bertram Heinrich Drost, Markus Ulrich, US Patent 8830229 (Sept. 9, 2014), assignee: MVTec Software GmbH, 81675 Muenchen (Germany). Further patents are pending. For further details, contact MVTec Software GmbH (info@mvtec.com).
Note that restrictions imposed by these patents (and possibly others) exist independently of and may be in conflict with the freedoms granted in this license, which refers to copyright of the program, not patents for any methods that it implements. Both copyright and patent law must be obeyed to legally use and redistribute this program and it is not the purpose of this license to induce you to infringe any patents or other property right claims or to contest validity of any such claims. If you redistribute or use the program, then this license merely protects you from committing copyright infringement. It does not protect you from committing patent infringement. So, before you do anything with this program, make sure that you have permission to do so not merely in terms of copyright, but also in terms of patent law.
Please note that this license is not to be understood as a guarantee either. If you use the program according to this license, but in conflict with patent law, it does not mean that the licensor will refund you for any losses that you incur if you are sued for your patent infringement.
Cameras and similar devices with the capability of sensation of 3D structure are becoming more common. Thus, using depth and intensity information for matching 3D objects (or parts) are of crucial importance for computer vision. Applications range from industrial control to guiding everyday actions for visually impaired people. The task in recognition and pose estimation in range images aims to identify and localize a queried 3D free-form object by matching it to the acquired database.
From an industrial perspective, enabling robots to automatically locate and pick up randomly placed and oriented objects from a bin is an important challenge in factory automation, replacing tedious and heavy manual labor. A system should be able to recognize and locate objects with a predefined shape and estimate the position with the precision necessary for a gripping robot to pick it up. This is where vision guided robotics takes the stage. Similar tools are also capable of guiding robots (and even people) through unstructured environments, leading to automated navigation. These properties make 3D matching from point clouds a ubiquitous necessity. Within this context, I will now describe the OpenCV implementation of a 3D object recognition and pose estimation algorithm using 3D features.
The state of the algorithms in order to achieve the task 3D matching is heavily based on [59], which is one of the first and main practical methods presented in this area. The approach is composed of extracting 3D feature points randomly from depth images or generic point clouds, indexing them and later in runtime querying them efficiently. Only the 3D structure is considered, and a trivial hash table is used for feature queries.
While being fully aware that utilization of the nice CAD model structure in order to achieve a smart point sampling, I will be leaving that aside now in order to respect the generalizability of the methods (Typically for such algorithms training on a CAD model is not needed, and a point cloud would be sufficient). Below is the outline of the entire algorithm:
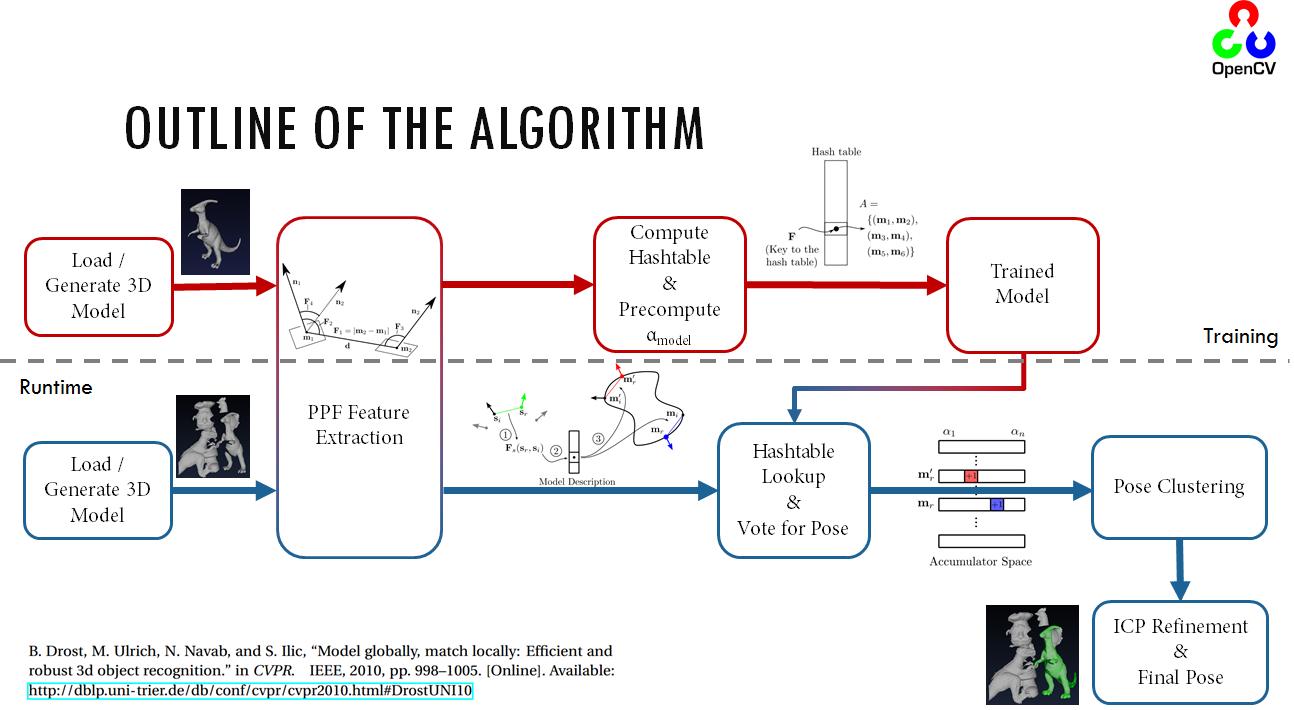
As explained, the algorithm relies on the extraction and indexing of point pair features, which are defined as follows:
\[\bf{{F}}(\bf{{m1}}, \bf{{m2}}) = (||\bf{{d}}||_2, <(\bf{{n1}},\bf{{d}}), <(\bf{{n2}},\bf{{d}}), <(\bf{{n1}},\bf{{n2}}))\]
where \(\bf{{m1}}\) and \(\bf{{m2}}\) are feature two selected points on the model (or scene), \(\bf{{d}}\) is the difference vector, \(\bf{{n1}}\) and \(\bf{{n2}}\) are the normals at \(\bf{{m1}}\) and \(\bf{m2}\). During the training stage, this vector is quantized, indexed. In the test stage, same features are extracted from the scene and compared to the database. With a few tricks like separation of the rotational components, the pose estimation part can also be made efficient (check the reference for more details). A Hough-like voting and clustering is employed to estimate the object pose. To cluster the poses, the raw pose hypotheses are sorted in decreasing order of the number of votes. From the highest vote, a new cluster is created. If the next pose hypothesis is close to one of the existing clusters, the hypothesis is added to the cluster and the cluster center is updated as the average of the pose hypotheses within the cluster. If the next hypothesis is not close to any of the clusters, it creates a new cluster. The proximity testing is done with fixed thresholds in translation and rotation. Distance computation and averaging for translation are performed in the 3D Euclidean space, while those for rotation are performed using quaternion representation. After clustering, the clusters are sorted in decreasing order of the total number of votes which determines confidence of the estimated poses.
This pose is further refined using \(ICP\) in order to obtain the final pose.
PPF presented above depends largely on robust computation of angles between 3D vectors. Even though not reported in the paper, the naive way of doing this ( \(\theta = cos^{-1}({\bf{a}}\cdot{\bf{b}})\) remains numerically unstable. A better way to do this is then use inverse tangents, like:
\[<(\bf{n1},\bf{n2})=tan^{-1}(||{\bf{n1} \wedge \bf{n2}}||_2, \bf{n1} \cdot \bf{n2})\]
Let me summarize the following notation:
The transformation in a point pair feature is computed by first finding the transformation \(T_{m\rightarrow g}\) from the first point, and applying the same transformation to the second one. Transforming each point, together with the normal, to the ground plane leaves us with an angle to find out, during a comparison with a new point pair.
We could now simply start writing
\[(p^i_m)^{'} = T_{m\rightarrow g} p^i_m\]
where
\[T_{m\rightarrow g} = -t_{m\rightarrow g}R_{m\rightarrow g}\]
Note that this is nothing but a stacked transformation. The translational component \(t_{m\rightarrow g}\) reads
\[t_{m\rightarrow g} = -R_{m\rightarrow g}p^i_m\]
and the rotational being
\[\theta_{m\rightarrow g} = \cos^{-1}(n^i_m \cdot {\bf{x}})\\ {\bf{R_{m\rightarrow g}}} = n^i_m \wedge {\bf{x}}\]
in axis angle format. Note that bold refers to the vector form. After this transformation, the feature vectors of the model are registered onto the ground plane X and the angle with respect to \(x=0\) is called \(\alpha_m\). Similarly, for the scene, it is called \(\alpha_s\).
As shown in the outline, PPF (point pair features) are extracted from the model, quantized, stored in the hashtable and indexed, during the training stage. During the runtime however, the similar operation is perfomed on the input scene with the exception that this time a similarity lookup over the hashtable is performed, instead of an insertion. This lookup also allows us to compute a transformation to the ground plane for the scene pairs. After this point, computing the rotational component of the pose reduces to computation of the difference \(\alpha=\alpha_m-\alpha_s\). This component carries the cue about the object pose. A Hough-like voting scheme is performed over the local model coordinate vector and \(\alpha\). The highest poses achieved for every scene point lets us recover the object pose.
The matching process terminates with the attainment of the pose. However, due to the multiple matching points, erroneous hypothesis, pose averaging and etc. such pose is very open to noise and many times is far from being perfect. Although the visual results obtained in that stage are pleasing, the quantitative evaluation shows \(~10\) degrees variation (error), which is an acceptable level of matching. Many times, the requirement might be set well beyond this margin and it is desired to refine the computed pose.
Furthermore, in typical RGBD scenes and point clouds, 3D structure can capture only less than half of the model due to the visibility in the scene. Therefore, a robust pose refinement algorithm, which can register occluded and partially visible shapes quickly and correctly is not an unrealistic wish.
At this point, a trivial option would be to use the well known iterative closest point algorithm . However, utilization of the basic ICP leads to slow convergence, bad registration, outlier sensitivity and failure to register partial shapes. Thus, it is definitely not suited to the problem. For this reason, many variants have been proposed . Different variants contribute to different stages of the pose estimation process.
ICP is composed of \(6\) stages and the improvements I propose for each stage is summarized below.
To improve convergence speed and computation time, it is common to use less points than the model actually has. However, sampling the correct points to register is an issue in itself. The naive way would be to sample uniformly and hope to get a reasonable subset. More smarter ways try to identify the critical points, which are found to highly contribute to the registration process. Gelfand et. al. exploit the covariance matrix in order to constrain the eigenspace, so that a set of points which affect both translation and rotation are used. This is a clever way of subsampling, which I will optionally be using in the implementation.
As the name implies, this step is actually the assignment of the points in the data and the model in a closest point fashion. Correct assignments will lead to a correct pose, where wrong assignments strongly degrade the result. In general, KD-trees are used in the search of nearest neighbors, to increase the speed. However this is not an optimality guarantee and many times causes wrong points to be matched. Luckily the assignments are corrected over iterations.
To overcome some of the limitations, Picky ICP [296] and BC-ICP (ICP using bi-unique correspondences) are two well-known methods. Picky ICP first finds the correspondences in the old-fashioned way and then among the resulting corresponding pairs, if more than one scene point \(p_i\) is assigned to the same model point \(m_j\), it selects \(p_i\) that corresponds to the minimum distance. BC-ICP on the other hand, allows multiple correspondences first and then resolves the assignments by establishing bi-unique correspondences. It also defines a novel no-correspondence outlier, which intrinsically eases the process of identifying outliers.
For reference, both methods are used. Because P-ICP is a bit faster, with not-so-significant performance drawback, it will be the method of choice in refinment of correspondences.
In my implementation, I currently do not use a weighting scheme. But the common approaches involve normal compatibility* ( \(w_i=n^1_i\cdot n^2_j\)) or assigning lower weights to point pairs with greater distances ( \(w=1-\frac{||dist(m_i,s_i)||_2}{dist_{max}}\)).
The rejections are done using a dynamic thresholding based on a robust estimate of the standard deviation. In other words, in each iteration, I find the MAD estimate of the Std. Dev. I denote this as \(mad_i\). I reject the pairs with distances \(d_i>\tau mad_i\). Here \(\tau\) is the threshold of rejection and by default set to \(3\). The weighting is applied prior to Picky refinement, explained in the previous stage.
As described in , a linearization of point to plane as in [152] error metric is used. This both speeds up the registration process and improves convergence.
Even though many non-linear optimizers (such as Levenberg Mardquardt) are proposed, due to the linearization in the previous step, pose estimation reduces to solving a linear system of equations. This is what I do exactly using cv::solve with DECOMP_SVD option.
Having described the steps above, here I summarize the layout of the ICP algorithm.
While the up-to-now-proposed variants deal well with some outliers and bad initializations, they require significant number of iterations. Yet, multi-resolution scheme can help reducing the number of iterations by allowing the registration to start from a coarse level and propagate to the lower and finer levels. Such approach both improves the performances and enhances the runtime.
The search is done through multiple levels, in a hierarchical fashion. The registration starts with a very coarse set of samples of the model. Iteratively, the points are densified and sought. After each iteration the previously estimated pose is used as an initial pose and refined with the ICP.
In all of the results, the pose is initiated by PPF and the rest is left as: \([\theta_x, \theta_y, \theta_z, t_x, t_y, t_z]=[0]\)
This section is dedicated to the results of surface matching (point-pair-feature matching and a following ICP refinement):

Matches of different models for Mian dataset is presented below:

You might checkout the video on youTube here.
Surface matching module treats its parameters relative to the model diameter (diameter of the axis parallel bounding box), whenever it can. This makes the parameters independent from the model size. This is why, both model and scene cloud were subsampled such that all points have a minimum distance of \(RelativeSamplingStep*DimensionRange\), where \(DimensionRange\) is the distance along a given dimension. All three dimensions are sampled in similar manner. For example, if \(RelativeSamplingStep\) is set to 0.05 and the diameter of model is 1m (1000mm), the points sampled from the object's surface will be approximately 50 mm apart. From another point of view, if the sampling RelativeSamplingStep is set to 0.05, at most \(20x20x20 = 8000\) model points are generated (depending on how the model fills in the volume). Consequently this results in at most 8000x8000 pairs. In practice, because the models are not uniformly distributed over a rectangular prism, much less points are to be expected. Decreasing this value, results in more model points and thus a more accurate representation. However, note that number of point pair features to be computed is now quadratically increased as the complexity is O(N\^2). This is especially a concern for 32 bit systems, where large models can easily overshoot the available memory. Typically, values in the range of 0.025 - 0.05 seem adequate for most of the applications, where the default value is 0.03. (Note that there is a difference in this paremeter with the one presented in [59] . In [59] a uniform cuboid is used for quantization and model diameter is used for reference of sampling. In my implementation, the cuboid is a rectangular prism, and each dimension is quantized independently. I do not take reference from the diameter but along the individual dimensions.
It would very wise to remove the outliers from the model and prepare an ideal model initially. This is because, the outliers directly affect the relative computations and degrade the matching accuracy.
During runtime stage, the scene is again sampled by \(RelativeSamplingStep\), as described above. However this time, only a portion of the scene points are used as reference. This portion is controlled by the parameter \(RelativeSceneSampleStep\), where \(SceneSampleStep = (int)(1.0/RelativeSceneSampleStep)\). In other words, if the \(RelativeSceneSampleStep = 1.0/5.0\), the subsampled scene will once again be uniformly sampled to 1/5 of the number of points. Maximum value of this parameter is 1 and increasing this parameter also increases the stability, but decreases the speed. Again, because of the initial scene-independent relative sampling, fine tuning this parameter is not a big concern. This would only be an issue when the model shape occupies a volume uniformly, or when the model shape is condensed in a tiny place within the quantization volume (e.g. The octree representation would have too much empty cells).
\(RelativeDistanceStep\) acts as a step of discretization over the hash table. The point pair features are quantized to be mapped to the buckets of the hashtable. This discretization involves a multiplication and a casting to the integer. Adjusting RelativeDistanceStep in theory controls the collision rate. Note that, more collisions on the hashtable results in less accurate estimations. Reducing this parameter increases the affect of quantization but starts to assign non-similar point pairs to the same bins. Increasing it however, wanes the ability to group the similar pairs. Generally, because during the sampling stage, the training model points are selected uniformly with a distance controlled by RelativeSamplingStep, RelativeDistanceStep is expected to equate to this value. Yet again, values in the range of 0.025-0.05 are sensible. This time however, when the model is dense, it is not advised to decrease this value. For noisy scenes, the value can be increased to improve the robustness of the matching against noisy points.
| typedef uint cv::ppf_match_3d::KeyType |
#include <opencv2/surface_matching/t_hash_int.hpp>
| typedef Ptr<Pose3D> cv::ppf_match_3d::Pose3DPtr |
#include <opencv2/surface_matching/pose_3d.hpp>
#include <opencv2/surface_matching/pose_3d.hpp>
| Mat cv::ppf_match_3d::addNoisePC | ( | Mat | pc, |
| double | scale | ||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.addNoisePC( | pc, scale | ) -> | retval | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Adds a uniform noise in the given scale to the input point cloud
| [in] | pc | Input point cloud (CV_32F family). |
| [in] | scale | Input scale of the noise. The larger the scale, the more noisy the output |
#include <opencv2/surface_matching/ppf_helpers.hpp>
| int cv::ppf_match_3d::computeNormalsPC3d | ( | const Mat & | PC, |
| Mat & | PCNormals, | ||
| const int | NumNeighbors, | ||
| const bool | FlipViewpoint, | ||
| const Vec3f & | viewpoint | ||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.computeNormalsPC3d( | PC, NumNeighbors, FlipViewpoint, viewpoint[, PCNormals] | ) -> | retval, PCNormals | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Compute the normals of an arbitrary point cloud computeNormalsPC3d uses a plane fitting approach to smoothly compute local normals. Normals are obtained through the eigenvector of the covariance matrix, corresponding to the smallest eigen value. If PCNormals is provided to be an Nx6 matrix, then no new allocation is made, instead the existing memory is overwritten.
| [in] | PC | Input point cloud to compute the normals for. |
| [out] | PCNormals | Output point cloud |
| [in] | NumNeighbors | Number of neighbors to take into account in a local region |
| [in] | FlipViewpoint | Should normals be flipped to a viewing direction? |
| [in] | viewpoint |
| void cv::ppf_match_3d::destroyFlann | ( | void * | flannIndex | ) |
#include <opencv2/surface_matching/ppf_helpers.hpp>
| void cv::ppf_match_3d::getRandomPose | ( | Matx44d & | Pose | ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.getRandomPose( | Pose | ) -> | None | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Generate a random 4x4 pose matrix
| [out] | Pose | The random pose |
| hashtable_int* cv::ppf_match_3d::hashtable_int_clone | ( | hashtable_int * | hashtbl | ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| hashtable_int* cv::ppf_match_3d::hashtableCreate | ( | size_t | size, |
| size_t(*)(uint) | hashfunc | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| void cv::ppf_match_3d::hashtableDestroy | ( | hashtable_int * | hashtbl | ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| void* cv::ppf_match_3d::hashtableGet | ( | hashtable_int * | hashtbl, |
| KeyType | key | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| hashnode_i* cv::ppf_match_3d::hashtableGetBucketHashed | ( | hashtable_int * | hashtbl, |
| KeyType | key | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| int cv::ppf_match_3d::hashtableInsert | ( | hashtable_int * | hashtbl, |
| KeyType | key, | ||
| void * | data | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| int cv::ppf_match_3d::hashtableInsertHashed | ( | hashtable_int * | hashtbl, |
| KeyType | key, | ||
| void * | data | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| void cv::ppf_match_3d::hashtablePrint | ( | hashtable_int * | hashtbl | ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| hashtable_int* cv::ppf_match_3d::hashtableRead | ( | FILE * | f | ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| int cv::ppf_match_3d::hashtableRemove | ( | hashtable_int * | hashtbl, |
| KeyType | key | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| int cv::ppf_match_3d::hashtableResize | ( | hashtable_int * | hashtbl, |
| size_t | size | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| int cv::ppf_match_3d::hashtableWrite | ( | const hashtable_int * | hashtbl, |
| const size_t | dataSize, | ||
| FILE * | f | ||
| ) |
#include <opencv2/surface_matching/t_hash_int.hpp>
| void* cv::ppf_match_3d::indexPCFlann | ( | Mat | pc | ) |
#include <opencv2/surface_matching/ppf_helpers.hpp>
| Mat cv::ppf_match_3d::loadPLYSimple | ( | const char * | fileName, |
| int | withNormals = 0 |
||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.loadPLYSimple( | fileName[, withNormals] | ) -> | retval | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Load a PLY file.
| [in] | fileName | The PLY model to read |
| [in] | withNormals | Flag wheather the input PLY contains normal information, and whether it should be loaded or not |
#include <opencv2/surface_matching/t_hash_int.hpp>
Round up to the next highest power of 2.
from http://www-graphics.stanford.edu/~seander/bithacks.html
| Mat cv::ppf_match_3d::normalizePCCoeff | ( | Mat | pc, |
| float | scale, | ||
| float * | Cx, | ||
| float * | Cy, | ||
| float * | Cz, | ||
| float * | MinVal, | ||
| float * | MaxVal | ||
| ) |
#include <opencv2/surface_matching/ppf_helpers.hpp>
#include <opencv2/surface_matching/ppf_helpers.hpp>
| void cv::ppf_match_3d::queryPCFlann | ( | void * | flannIndex, |
| Mat & | pc, | ||
| Mat & | indices, | ||
| Mat & | distances, | ||
| const int | numNeighbors | ||
| ) |
#include <opencv2/surface_matching/ppf_helpers.hpp>
| Mat cv::ppf_match_3d::samplePCByQuantization | ( | Mat | pc, |
| Vec2f & | xrange, | ||
| Vec2f & | yrange, | ||
| Vec2f & | zrange, | ||
| float | sample_step_relative, | ||
| int | weightByCenter = 0 |
||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.samplePCByQuantization( | pc, xrange, yrange, zrange, sample_step_relative[, weightByCenter] | ) -> | retval | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Sample a point cloud using uniform steps
| [in] | pc | Input point cloud |
| [in] | xrange | X components (min and max) of the bounding box of the model |
| [in] | yrange | Y components (min and max) of the bounding box of the model |
| [in] | zrange | Z components (min and max) of the bounding box of the model |
| [in] | sample_step_relative | The point cloud is sampled such that all points have a certain minimum distance. This minimum distance is determined relatively using the parameter sample_step_relative. |
| [in] | weightByCenter | The contribution of the quantized data points can be weighted by the distance to the origin. This parameter enables/disables the use of weighting. |
#include <opencv2/surface_matching/ppf_helpers.hpp>
#include <opencv2/surface_matching/ppf_helpers.hpp>
| Mat cv::ppf_match_3d::transformPCPose | ( | Mat | pc, |
| const Matx44d & | Pose | ||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.transformPCPose( | pc, Pose | ) -> | retval | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Transforms the point cloud with a given a homogeneous 4x4 pose matrix (in double precision)
| [in] | pc | Input point cloud (CV_32F family). Point clouds with 3 or 6 elements per row are expected. In the case where the normals are provided, they are also rotated to be compatible with the entire transformation |
| [in] | Pose | 4x4 pose matrix, but linearized in row-major form. |
| Mat cv::ppf_match_3d::transPCCoeff | ( | Mat | pc, |
| float | scale, | ||
| float | Cx, | ||
| float | Cy, | ||
| float | Cz, | ||
| float | MinVal, | ||
| float | MaxVal | ||
| ) |
#include <opencv2/surface_matching/ppf_helpers.hpp>
| void cv::ppf_match_3d::writePLY | ( | Mat | PC, |
| const char * | fileName | ||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.writePLY( | PC, fileName | ) -> | None | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Write a point cloud to PLY file.
| [in] | PC | Input point cloud |
| [in] | fileName | The PLY model file to write |
| void cv::ppf_match_3d::writePLYVisibleNormals | ( | Mat | PC, |
| const char * | fileName | ||
| ) |
| Python: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv.ppf_match_3d.writePLYVisibleNormals( | PC, fileName | ) -> | None | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
#include <opencv2/surface_matching/ppf_helpers.hpp>
Used for debbuging pruposes, writes a point cloud to a PLY file with the tip of the normal vectors as visible red points.
| [in] | PC | Input point cloud |
| [in] | fileName | The PLY model file to write |
 1.8.13
1.8.13