|
OpenCV 4.13.0-dev
Open Source Computer Vision
|
Loading...
Searching...
No Matches
|
OpenCV 4.13.0-dev
Open Source Computer Vision
|
Prev Tutorial: Support Vector Machines for Non-Linearly Separable Data
| Original author | Theodore Tsesmelis |
| Compatibility | OpenCV >= 3.0 |
In this tutorial you will learn how to:
Principal Component Analysis (PCA) is a statistical procedure that extracts the most important features of a dataset.
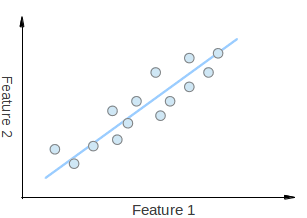
Consider that you have a set of 2D points as it is shown in the figure above. Each dimension corresponds to a feature you are interested in. Here some could argue that the points are set in a random order. However, if you have a better look you will see that there is a linear pattern (indicated by the blue line) which is hard to dismiss. A key point of PCA is the Dimensionality Reduction. Dimensionality Reduction is the process of reducing the number of the dimensions of the given dataset. For example, in the above case it is possible to approximate the set of points to a single line and therefore, reduce the dimensionality of the given points from 2D to 1D.
Moreover, you could also see that the points vary the most along the blue line, more than they vary along the Feature 1 or Feature 2 axes. This means that if you know the position of a point along the blue line you have more information about the point than if you only knew where it was on Feature 1 axis or Feature 2 axis.
Hence, PCA allows us to find the direction along which our data varies the most. In fact, the result of running PCA on the set of points in the diagram consist of 2 vectors called eigenvectors which are the principal components of the data set.
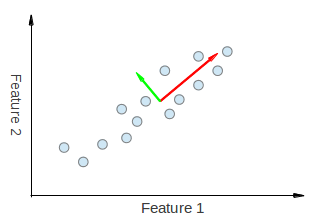
The size of each eigenvector is encoded in the corresponding eigenvalue and indicates how much the data vary along the principal component. The beginning of the eigenvectors is the center of all points in the data set. Applying PCA to N-dimensional data set yields N N-dimensional eigenvectors, N eigenvalues and 1 N-dimensional center point. Enough theory, let’s see how we can put these ideas into code.
The goal is to transform a given data set X of dimension p to an alternative data set Y of smaller dimension L. Equivalently, we are seeking to find the matrix Y, where Y is the Karhunen–Loève transform (KLT) of matrix X:
\[ \mathbf{Y} = \mathbb{K} \mathbb{L} \mathbb{T} \{\mathbf{X}\} \]
Organize the data set
Suppose you have data comprising a set of observations of p variables, and you want to reduce the data so that each observation can be described with only L variables, L < p. Suppose further, that the data are arranged as a set of n data vectors \( x_1...x_n \) with each \( x_i \) representing a single grouped observation of the p variables.
Calculate the empirical mean
Place the calculated mean values into an empirical mean vector u of dimensions \( p\times 1 \).
\[ \mathbf{u[j]} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{X[i,j]} \]
Calculate the deviations from the mean
Mean subtraction is an integral part of the solution towards finding a principal component basis that minimizes the mean square error of approximating the data. Hence, we proceed by centering the data as follows:
Store mean-subtracted data in the \( n\times p \) matrix B.
\[ \mathbf{B} = \mathbf{X} - \mathbf{h}\mathbf{u^{T}} \]
where h is an \( n\times 1 \) column vector of all 1s:
\[ h[i] = 1, i = 1, ..., n \]
Find the covariance matrix
Find the \( p\times p \) empirical covariance matrix C from the outer product of matrix B with itself:
\[ \mathbf{C} = \frac{1}{n-1} \mathbf{B^{*}} \cdot \mathbf{B} \]
where * is the conjugate transpose operator. Note that if B consists entirely of real numbers, which is the case in many applications, the "conjugate transpose" is the same as the regular transpose.
Find the eigenvectors and eigenvalues of the covariance matrix
Compute the matrix V of eigenvectors which diagonalizes the covariance matrix C:
\[ \mathbf{V^{-1}} \mathbf{C} \mathbf{V} = \mathbf{D} \]
where D is the diagonal matrix of eigenvalues of C.
Matrix D will take the form of an \( p \times p \) diagonal matrix:
\[ D[k,l] = \left\{\begin{matrix} \lambda_k, k = l \\ 0, k \neq l \end{matrix}\right. \]
here, \( \lambda_j \) is the j-th eigenvalue of the covariance matrix C
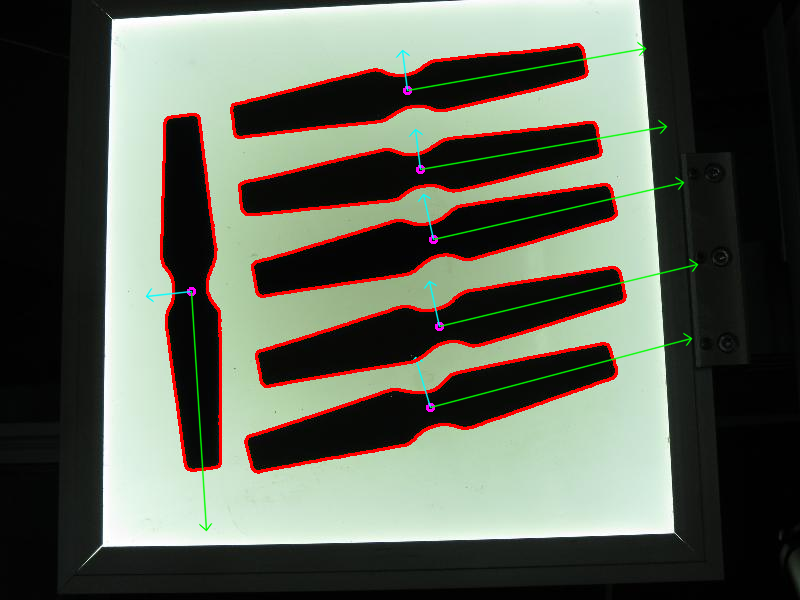
Here we apply the necessary pre-processing procedures in order to be able to detect the objects of interest.
Then find and filter contours by size and obtain the orientation of the remaining ones.
Orientation is extracted by the call of getOrientation() function, which performs all the PCA procedure.
First the data need to be arranged in a matrix with size n x 2, where n is the number of data points we have. Then we can perform that PCA analysis. The calculated mean (i.e. center of mass) is stored in the cntr variable and the eigenvectors and eigenvalues are stored in the corresponding std::vector’s.
The final result is visualized through the drawAxis() function, where the principal components are drawn in lines, and each eigenvector is multiplied by its eigenvalue and translated to the mean position.
The code opens an image, finds the orientation of the detected objects of interest and then visualizes the result by drawing the contours of the detected objects of interest, the center point, and the x-axis, y-axis regarding the extracted orientation.