|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Loading...
Searching...
No Matches
|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Optical flow is the pattern of apparent motion of image objects between two consecutive frames caused by the movement of object or camera. It is 2D vector field where each vector is a displacement vector showing the movement of points from first frame to second. Consider the image below (Image Courtesy: Wikipedia article on Optical Flow).
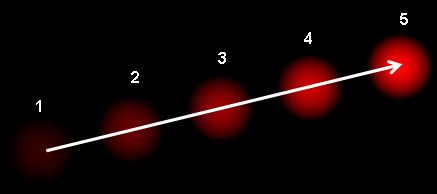
It shows a ball moving in 5 consecutive frames. The arrow shows its displacement vector. Optical flow has many applications in areas like :
Optical flow works on several assumptions:
Consider a pixel \(I(x,y,t)\) in first frame (Check a new dimension, time, is added here. Earlier we were working with images only, so no need of time). It moves by distance \((dx,dy)\) in next frame taken after \(dt\) time. So since those pixels are the same and intensity does not change, we can say,
\[I(x,y,t) = I(x+dx, y+dy, t+dt)\]
Then take taylor series approximation of right-hand side, remove common terms and divide by \(dt\) to get the following equation:
\[f_x u + f_y v + f_t = 0 \;\]
where:
\[f_x = \frac{\partial f}{\partial x} \; ; \; f_y = \frac{\partial f}{\partial y}\]
\[u = \frac{dx}{dt} \; ; \; v = \frac{dy}{dt}\]
Above equation is called Optical Flow equation. In it, we can find \(f_x\) and \(f_y\), they are image gradients. Similarly \(f_t\) is the gradient along time. But \((u,v)\) is unknown. We cannot solve this one equation with two unknown variables. So several methods are provided to solve this problem and one of them is Lucas-Kanade.
We have seen an assumption before, that all the neighbouring pixels will have similar motion. Lucas-Kanade method takes a 3x3 patch around the point. So all the 9 points have the same motion. We can find \((f_x, f_y, f_t)\) for these 9 points. So now our problem becomes solving 9 equations with two unknown variables which is over-determined. A better solution is obtained with least square fit method. Below is the final solution which is two equation-two unknown problem and solve to get the solution.
\[\begin{bmatrix} u \\ v \end{bmatrix} = \begin{bmatrix} \sum_{i}{f_{x_i}}^2 & \sum_{i}{f_{x_i} f_{y_i} } \\ \sum_{i}{f_{x_i} f_{y_i}} & \sum_{i}{f_{y_i}}^2 \end{bmatrix}^{-1} \begin{bmatrix} - \sum_{i}{f_{x_i} f_{t_i}} \\ - \sum_{i}{f_{y_i} f_{t_i}} \end{bmatrix}\]
( Check similarity of inverse matrix with Harris corner detector. It denotes that corners are better points to be tracked.)
So from user point of view, idea is simple, we give some points to track, we receive the optical flow vectors of those points. But again there are some problems. Until now, we were dealing with small motions. So it fails when there is large motion. So again we go for pyramids. When we go up in the pyramid, small motions are removed and large motions becomes small motions. So applying Lucas-Kanade there, we get optical flow along with the scale.
We use the function: cv.calcOpticalFlowPyrLK (prevImg, nextImg, prevPts, nextPts, status, err, winSize = new cv.Size(21, 21), maxLevel = 3, criteria = new cv.TermCriteria(cv.TermCriteria_COUNT+ cv.TermCriteria_EPS, 30, 0.01), flags = 0, minEigThreshold = 1e-4).
| prevImg | first 8-bit input image or pyramid constructed by buildOpticalFlowPyramid. |
| nextImg | second input image or pyramid of the same size and the same type as prevImg. |
| prevPts | vector of 2D points for which the flow needs to be found; point coordinates must be single-precision floating-point numbers. |
| nextPts | output vector of 2D points (with single-precision floating-point coordinates) containing the calculated new positions of input features in the second image; when cv.OPTFLOW_USE_ INITIAL_FLOW flag is passed, the vector must have the same size as in the input. |
| status | output status vector (of unsigned chars); each element of the vector is set to 1 if the flow for the corresponding features has been found, otherwise, it is set to 0. |
| err | output vector of errors; each element of the vector is set to an error for the corresponding feature, type of the error measure can be set in flags parameter; if the flow wasn't found then the error is not defined (use the status parameter to find such cases). |
| winSize | size of the search window at each pyramid level. |
| maxLevel | 0-based maximal pyramid level number; if set to 0, pyramids are not used (single level), if set to 1, two levels are used, and so on; if pyramids are passed to input then algorithm will use as many levels as pyramids have but no more than maxLevel. |
| criteria | parameter, specifying the termination criteria of the iterative search algorithm (after the specified maximum number of iterations criteria.maxCount or when the search window moves by less than criteria.epsilon. |
| flags | operation flags:
|
| minEigThreshold | the algorithm calculates the minimum eigen value of a 2x2 normal matrix of optical flow equations, divided by number of pixels in a window; if this value is less than minEigThreshold, then a corresponding feature is filtered out and its flow is not processed, so it allows to remove bad points and get a performance boost. |
(This code doesn't check how correct are the next keypoints. So even if any feature point disappears in image, there is a chance that optical flow finds the next point which may look close to it. So actually for a robust tracking, corner points should be detected in particular intervals.)
Lucas-Kanade method computes optical flow for a sparse feature set (in our example, corners detected using Shi-Tomasi algorithm). OpenCV.js provides another algorithm to find the dense optical flow. It computes the optical flow for all the points in the frame. It is based on Gunnar Farneback's algorithm which is explained in "Two-Frame Motion Estimation Based on Polynomial Expansion" by Gunnar Farneback in 2003.
We use the function: cv.calcOpticalFlowFarneback (prev, next, flow, pyrScale, levels, winsize, iterations, polyN, polySigma, flags)
| prev | first 8-bit single-channel input image. |
| next | second input image of the same size and the same type as prev. |
| flow | computed flow image that has the same size as prev and type CV_32FC2. |
| pyrScale | parameter, specifying the image scale (<1) to build pyramids for each image; pyrScale=0.5 means a classical pyramid, where each next layer is twice smaller than the previous one. |
| levels | number of pyramid layers including the initial image; levels=1 means that no extra layers are created and only the original images are used. |
| winsize | averaging window size; larger values increase the algorithm robustness to image noise and give more chances for fast motion detection, but yield more blurred motion field. |
| iterations | number of iterations the algorithm does at each pyramid level. |
| polyN | size of the pixel neighborhood used to find polynomial expansion in each pixel; larger values mean that the image will be approximated with smoother surfaces, yielding more robust algorithm and more blurred motion field, typically polyN =5 or 7. |
| polySigma | standard deviation of the Gaussian that is used to smooth derivatives used as a basis for the polynomial expansion; for polyN=5, you can set polySigma=1.1, for polyN=7, a good value would be polySigma=1.5. |
| flags | operation flags that can be a combination of the following:
|