|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Loading...
Searching...
No Matches
|
OpenCV 4.14.0-pre
Open Source Computer Vision
|
Prev Tutorial: File Input and Output using XML / YAML / JSON files
| Compatibility | OpenCV >= 3.0 |
The goal of this tutorial is to show you how to use the OpenCV parallel_for_ framework to easily parallelize your code. To illustrate the concept, we will write a program to draw a Mandelbrot set exploiting almost all the CPU load available. The full tutorial code is here. If you want more information about multithreading, you will have to refer to a reference book or course as this tutorial is intended to remain simple.
The first precondition is to have OpenCV built with a parallel framework. In OpenCV 3.2, the following parallel frameworks are available in that order:
As you can see, several parallel frameworks can be used in the OpenCV library. Some parallel libraries are third party libraries and have to be explicitly built and enabled in CMake (e.g. TBB, C=), others are automatically available with the platform (e.g. APPLE GCD) but chances are that you should be enable to have access to a parallel framework either directly or by enabling the option in CMake and rebuild the library.
The second (weak) precondition is more related to the task you want to achieve as not all computations are suitable / can be adapted to be run in a parallel way. To remain simple, tasks that can be split into multiple elementary operations with no memory dependency (no possible race condition) are easily parallelizable. Computer vision processing are often easily parallelizable as most of the time the processing of one pixel does not depend to the state of other pixels.
We will use the example of drawing a Mandelbrot set to show how from a regular sequential code you can easily adapt the code to parallelize the computation.
The Mandelbrot set definition has been named in tribute to the mathematician Benoit Mandelbrot by the mathematician Adrien Douady. It has been famous outside of the mathematics field as the image representation is an example of a class of fractals, a mathematical set that exhibits a repeating pattern displayed at every scale (even more, a Mandelbrot set is self-similar as the whole shape can be repeatedly seen at different scale). For a more in-depth introduction, you can look at the corresponding Wikipedia article. Here, we will just introduce the formula to draw the Mandelbrot set (from the mentioned Wikipedia article).
The Mandelbrot set is the set of values of \( c \) in the complex plane for which the orbit of 0 under iteration of the quadratic map
\[\begin{cases} z_0 = 0 \\ z_{n+1} = z_n^2 + c \end{cases}\]
remains bounded. That is, a complex number \( c \) is part of the Mandelbrot set if, when starting with \( z_0 = 0 \) and applying the iteration repeatedly, the absolute value of \( z_n \) remains bounded however large \( n \) gets. This can also be represented as
\[\limsup_{n\to\infty}|z_{n+1}|\leqslant2\]
A simple algorithm to generate a representation of the Mandelbrot set is called the "escape time algorithm". For each pixel in the rendered image, we test using the recurrence relation if the complex number is bounded or not under a maximum number of iterations. Pixels that do not belong to the Mandelbrot set will escape quickly whereas we assume that the pixel is in the set after a fixed maximum number of iterations. A high value of iterations will produce a more detailed image but the computation time will increase accordingly. We use the number of iterations needed to "escape" to depict the pixel value in the image.
To relate between the pseudocode and the theory, we have:
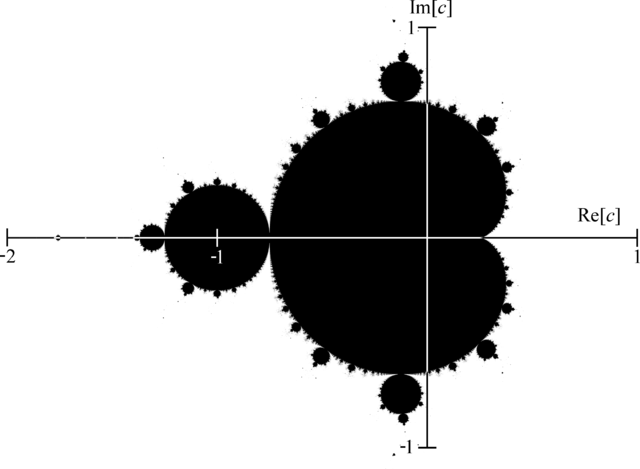
On this figure, we recall that the real part of a complex number is on the x-axis and the imaginary part on the y-axis. You can see that the whole shape can be repeatedly visible if we zoom at particular locations.
Here, we used the std::complex template class to represent a complex number. This function performs the test to check if the pixel is in set or not and returns the "escaped" iteration.
In this implementation, we sequentially iterate over the pixels in the rendered image to perform the test to check if the pixel is likely to belong to the Mandelbrot set or not.
Another thing to do is to transform the pixel coordinate into the Mandelbrot set space with:
Finally, to assign the grayscale value to the pixels, we use the following rule:
Using a linear scale transformation is not enough to perceive the grayscale variation. To overcome this, we will boost the perception by using a square root scale transformation (borrowed from Jeremy D. Frens in his blog post): \( f \left( x \right) = \sqrt{\frac{x}{\text{maxIter}}} \times 255 \)
The green curve corresponds to a simple linear scale transformation, the blue one to a square root scale transformation and you can observe how the lowest values will be boosted when looking at the slope at these positions.
When looking at the sequential implementation, we can notice that each pixel is computed independently. To optimize the computation, we can perform multiple pixel calculations in parallel, by exploiting the multi-core architecture of modern processor. To achieve this easily, we will use the OpenCV cv::parallel_for_ framework.
The first thing is to declare a custom class that inherits from cv::ParallelLoopBody and to override the virtual void operator ()(const cv::Range& range) const.
The range in the operator () represents the subset of pixels that will be treated by an individual thread. This splitting is done automatically to distribute equally the computation load. We have to convert the pixel index coordinate to a 2D [row, col] coordinate. Also note that we have to keep a reference on the mat image to be able to modify in-place the image.
The parallel execution is called with:
Here, the range represents the total number of operations to be executed, so the total number of pixels in the image. To set the number of threads, you can use: cv::setNumThreads. You can also specify the number of splitting using the nstripes parameter in cv::parallel_for_. For instance, if your processor has 4 threads, setting cv::setNumThreads(2) or setting nstripes=2 should be the same as by default it will use all the processor threads available but will split the workload only on two threads.
ParallelMandelbrot class and replacing it with lambda expression:You can find the full tutorial code here. The performance of the parallel implementation depends of the type of CPU you have. For instance, on 4 cores / 8 threads CPU, you can expect a speed-up of around 6.9X. There are many factors to explain why we do not achieve a speed-up of almost 8X. Main reasons should be mostly due to:
The resulting image produced by the tutorial code (you can modify the code to use more iterations and assign a pixel color depending on the escaped iteration and using a color palette to get more aesthetic images): 