|
OpenCV
4.5.5
Open Source Computer Vision
|
|
OpenCV
4.5.5
Open Source Computer Vision
|
Prev Tutorial: File Input and Output using XML and YAML files
Next Tutorial: Vectorizing your code using Universal Intrinsics
| Compatibility | OpenCV >= 3.0 |
The goal of this tutorial is to demonstrate the use of the OpenCV parallel_for_ framework to easily parallelize your code. To illustrate the concept, we will write a program to perform convolution operation over an image. The full tutorial code is here.
The first precondition is to have OpenCV built with a parallel framework. In OpenCV 4.5, the following parallel frameworks are available in that order:
As you can see, several parallel frameworks can be used in the OpenCV library. Some parallel libraries are third party libraries and have to be explicitly enabled in CMake before building, while others are automatically available with the platform (e.g. APPLE GCD).
Race conditions occur when more than one thread try to write or read and write to a particular memory location simultaneously. Based on that, we can broadly classify algorithms into two categories:-
We will use the example of performing a convolution to demonstrate the use of parallel_for_ to parallelize the computation. This is an example of an algorithm which does not lead to a race condition.
Convolution is a simple mathematical operation widely used in image processing. Here, we slide a smaller matrix, called the kernel, over an image and a sum of the product of pixel values and corresponding values in the kernel gives us the value of the particular pixel in the output (called the anchor point of the kernel). Based on the values in the kernel, we get different results. In the example below, we use a 3x3 kernel (anchored at its center) and convolve over a 5x5 matrix to produce a 3x3 matrix. The size of the output can be altered by padding the input with suitable values.
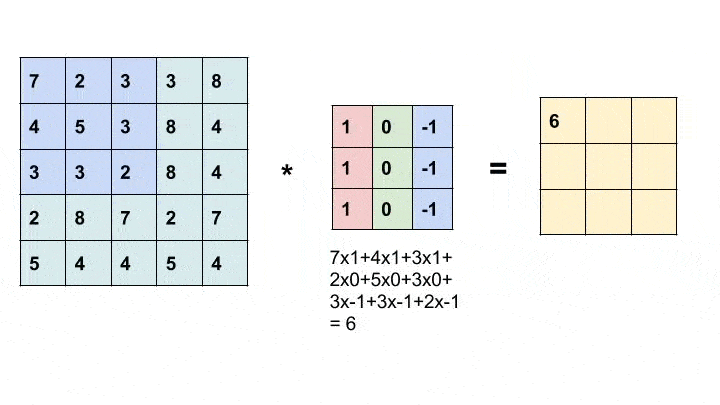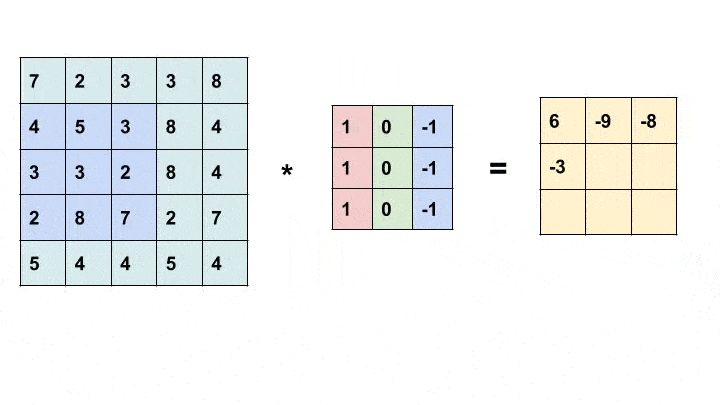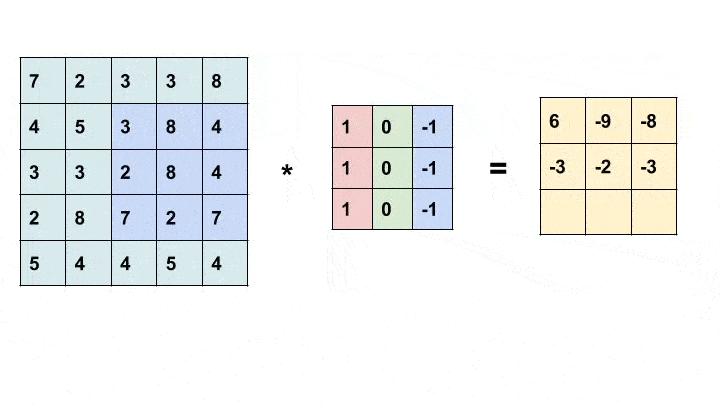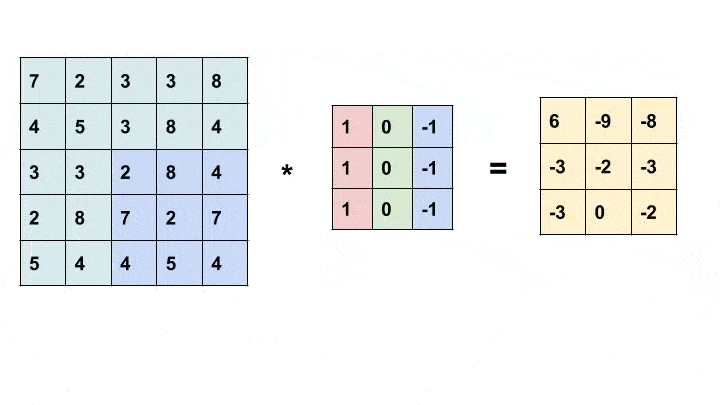
For more information about different kernels and what they do, look here
For the purpose of this tutorial, we will implement the simplest form of the function which takes a grayscale image (1 channel) and an odd length square kernel and produces an output image. The operation will not be performed in-place.
InputImage src, OutputImage dst, kernel(size n)
makeborder(src, n/2)
for each pixel (i, j) strictly inside borders, do:
{
value := 0
for k := -n/2 to n/2, do:
for l := -n/2 to n/2, do:
value += kernel[n/2 + k][n/2 + l]*src[i + k][j + l]
dst[i][j] := value
}
For an n-sized kernel, we will add a border of size n/2 to handle edge cases. We then run two loops to move along the kernel and add the products to sum
We first make an output matrix(dst) with the same size as src and add borders to the src image(to handle edge cases).
We then sequentially iterate over the pixels in the src image and compute the value over the kernel and the neighbouring pixel values. We then fill value to the corresponding pixel in the dst image.
When looking at the sequential implementation, we can notice that each pixel depends on multiple neighbouring pixels but only one pixel is edited at a time. Thus, to optimize the computation, we can split the image into stripes and parallely perform convolution on each, by exploiting the multi-core architecture of modern processor. The OpenCV cv::parallel_for_ framework automatically decides how to split the computation efficiently and does most of the work for us.
We first declare a custom class that inherits from cv::ParallelLoopBody and override the virtual void operator ()(const cv::Range& range) const.
The range in the operator () represents the subset of values that will be treated by an individual thread. Based on the requirement, there may be different ways of splitting the range which in turn changes the computation.
For example, we can either
Split the entire traversal of the image and obtain the [row, col] coordinate in the following way (as shown in the above code):
We would then call the parallel_for_ function in the following way:
Split the rows and compute for each row:
In this case, we call the parallel_for_ function with a different range:
To set the number of threads, you can use: cv::setNumThreads. You can also specify the number of splitting using the nstripes parameter in cv::parallel_for_. For instance, if your processor has 4 threads, setting cv::setNumThreads(2) or setting nstripes=2 should be the same as by default it will use all the processor threads available but will split the workload only on two threads.
parallelConvolution class and replacing it with lambda expression:The resulting time taken for execution of the two implementations on a
This program shows how to use the OpenCV parallel_for_ function and compares the performance of the sequential and parallel implementations for a convolution operation Usage: ./a.out [image_path -- default lena.jpg] Sequential Implementation: 0.0953564s Parallel Implementation: 0.0246762s Parallel Implementation(Row Split): 0.0248722s
This program shows how to use the OpenCV parallel_for_ function and compares the performance of the sequential and parallel implementations for a convolution operation Usage: ./a.out [image_path -- default lena.jpg] Sequential Implementation: 0.0301325s Parallel Implementation: 0.0117053s Parallel Implementation(Row Split): 0.0117894s
The performance of the parallel implementation depends on the type of CPU you have. For instance, on 4 cores - 8 threads CPU, runtime may be 6x to 7x faster than a sequential implementation. There are many factors to explain why we do not achieve a speed-up of 8x:
In the tutorial, we used a horizontal gradient filter(as shown in the animation above), which produces an image highlighting the vertical edges.

 1.8.13
1.8.13