|
OpenCV
4.0.0
Open Source Computer Vision
|
|
OpenCV
4.0.0
Open Source Computer Vision
|

This application helps to train your own face landmark detector. You can train your own face landmark detection by just providing the paths for directory containing the images and files containing their corresponding face landmarks. As this landmark detector was originally trained on HELEN dataset, the training follows the format of data provided in HELEN dataset.
The dataset consists of .txt files whose first line contains the image name which then follows the annotations. The format of the file containing annotations should be of following format :
/directory/images/abc.jpg 123.45,345.65 321.67,543.89 .... , .... .... , ....
The above format is similar to HELEN dataset which is used for training the model.
- annotations a : (REQUIRED) Path to annotations txt file [example - /data/annotations.txt]
- config c : (REQUIRED) Path to configuration xml file containing parameters for training.[ example - /data/config.xml]
- model m : (REQUIRED) Path to configuration xml file containing parameters for training.[ example - /data/model.dat]
- width w : (OPTIONAL) The width which you want all images to get to scale the annotations. Large images are slow to process [default = 460]
- height h : (OPTIONAL) The height which you want all images to get to scale the annotations. Large images are slow to process [default = 460]
- face_cascade f (REQUIRED) Path to the face cascade xml file which you want to use as a detector.
The configuration file described above which is used while training contains the training parameters which are required for training.
The description of parameters is as follows :
To get more detailed description about the training parameters you can refer to the Research paper.

Jumping directly to the code :
The facemark API provides the functionality to the user to use their own face detector to be used in training.The above code creartes a sample face detector. The above function would be passed to a function pointer in the facemark API.
The above code creates a vector filenames for storing the names of the .txt files. It gets the filenames of the files in the directory.
The above code creates a pointer of the face landmark detection class. The face detector created above has to be passed as function pointer to the facemark pointer created for detecting faces while training the model.
The above code creates std::vectors to store the images and their corresponding landmarks. The above code calls a function loadTrainingData to load the landmarks and the images into their respective vectors.
If the dataset you downloaded is of the following format :
Then skip the above code for loading training data and use the following code. This sample is provided as sampleTrainLandmarkDetector2.cpp in the face module in opencv contrib.
In the above code imagelist and annotations are the file of following format :
These symbolize the names of images and their corresponding annotations.
The above code scales images and landmarks as training on images of smaller size takes less time. This is because processing larger images requires more time. After scaling data it calculates mean shape of the data which is used as initial shape while training.
Finally call the following function to perform training :
In the above function scale is passed to scale all images and the corresponding landmarks so that the size of all images can be reduced as it takes greater time to process large images. This call to the train function trains the model and stores the trained model file with the given filename specified.As the training starts successfully you will see something like this :

The error rate on trained images depends on the number of images used for training used as follows :
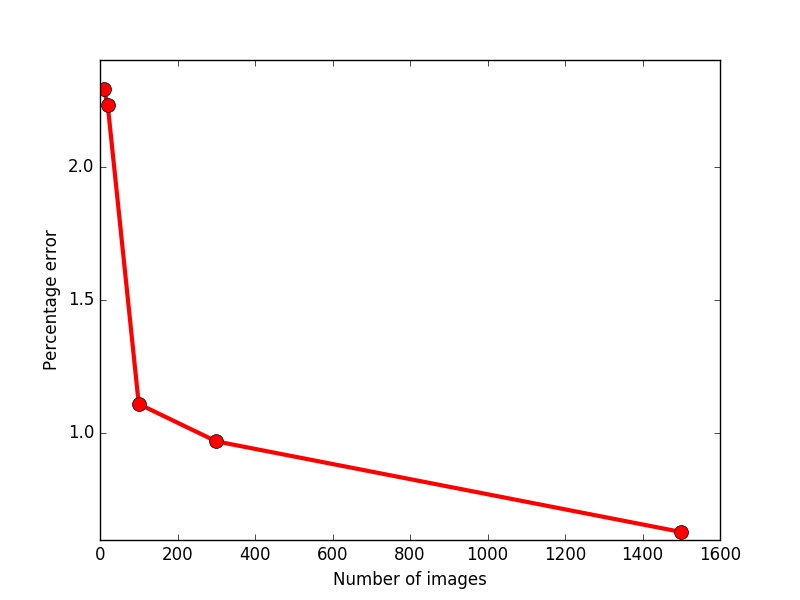
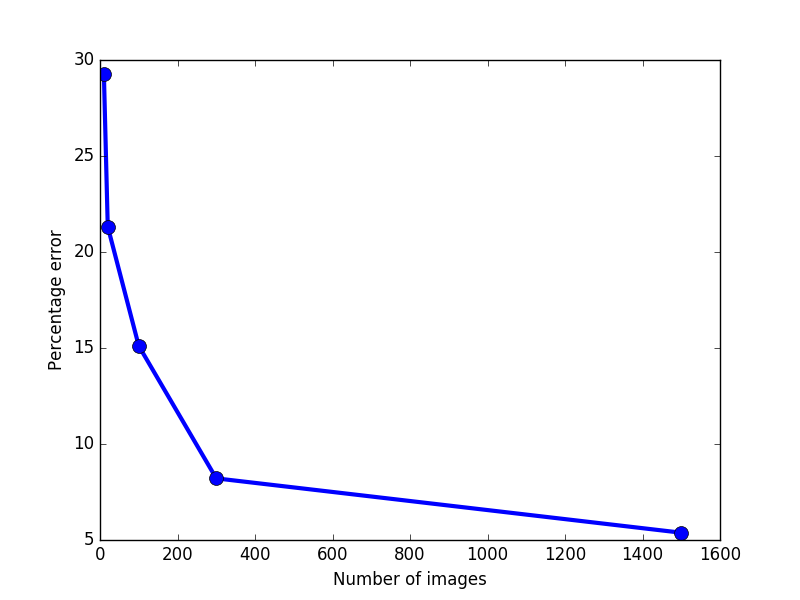
The error rate on test images depends on the number of images used for training used as follows :
 1.8.12
1.8.12