|
OpenCV
4.0.0-beta
Open Source Computer Vision
|
|
OpenCV
4.0.0-beta
Open Source Computer Vision
|
Nowadays, augmented reality is one of the top research topic in computer vision and robotics fields. The most elemental problem in augmented reality is the estimation of the camera pose respect of an object in the case of computer vision area to do later some 3D rendering or in the case of robotics obtain an object pose in order to grasp it and do some manipulation. However, this is not a trivial problem to solve due to the fact that the most common issue in image processing is the computational cost of applying a lot of algorithms or mathematical operations for solving a problem which is basic and immediately for humans.
In this tutorial is explained how to build a real time application to estimate the camera pose in order to track a textured object with six degrees of freedom given a 2D image and its 3D textured model.
The application will have the following parts:
In computer vision estimate the camera pose from n 3D-to-2D point correspondences is a fundamental and well understood problem. The most general version of the problem requires estimating the six degrees of freedom of the pose and five calibration parameters: focal length, principal point, aspect ratio and skew. It could be established with a minimum of 6 correspondences, using the well known Direct Linear Transform (DLT) algorithm. There are, though, several simplifications to the problem which turn into an extensive list of different algorithms that improve the accuracy of the DLT.
The most common simplification is to assume known calibration parameters which is the so-called Perspective-*n*-Point problem:
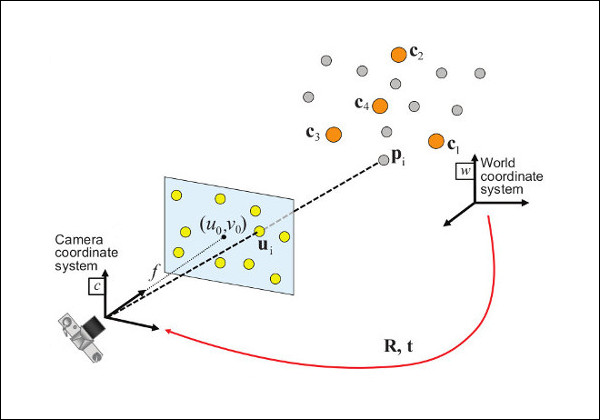
Problem Formulation: Given a set of correspondences between 3D points \(p_i\) expressed in a world reference frame, and their 2D projections \(u_i\) onto the image, we seek to retrieve the pose ( \(R\) and \(t\)) of the camera w.r.t. the world and the focal length \(f\).
OpenCV provides four different approaches to solve the Perspective-*n*-Point problem which return \(R\) and \(t\). Then, using the following formula it's possible to project 3D points into the image plane:
\[s\ \left [ \begin{matrix} u \\ v \\ 1 \end{matrix} \right ] = \left [ \begin{matrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{matrix} \right ] \left [ \begin{matrix} r_{11} & r_{12} & r_{13} & t_1 \\ r_{21} & r_{22} & r_{23} & t_2 \\ r_{31} & r_{32} & r_{33} & t_3 \end{matrix} \right ] \left [ \begin{matrix} X \\ Y \\ Z\\ 1 \end{matrix} \right ]\]
The complete documentation of how to manage with this equations is in Camera Calibration and 3D Reconstruction .
You can find the source code of this tutorial in the samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/ folder of the OpenCV source library.
The tutorial consists of two main programs:
Model registration
This application is exclusive to whom don't have a 3D textured model of the object to be detected. You can use this program to create your own textured 3D model. This program only works for planar objects, then if you want to model an object with complex shape you should use a sophisticated software to create it.
The application needs an input image of the object to be registered and its 3D mesh. We have also to provide the intrinsic parameters of the camera with which the input image was taken. All the files need to be specified using the absolute path or the relative one from your application’s working directory. If none files are specified the program will try to open the provided default parameters.
The application starts up extracting the ORB features and descriptors from the input image and then uses the mesh along with the Möller–Trumbore intersection algorithm to compute the 3D coordinates of the found features. Finally, the 3D points and the descriptors are stored in different lists in a file with YAML format which each row is a different point. The technical background on how to store the files can be found in the File Input and Output using XML and YAML files tutorial.

Model detection
The aim of this application is estimate in real time the object pose given its 3D textured model.
The application starts up loading the 3D textured model in YAML file format with the same structure explained in the model registration program. From the scene, the ORB features and descriptors are detected and extracted. Then, is used cv::FlannBasedMatcher with cv::flann::GenericIndex to do the matching between the scene descriptors and the model descriptors. Using the found matches along with cv::solvePnPRansac function the R and t of the camera are computed. Finally, a KalmanFilter is applied in order to reject bad poses.
In the case that you compiled OpenCV with the samples, you can find it in opencv/build/bin/cpp-tutorial-pnp_detection`. Then you can run the application and change some parameters:
For example, you can run the application changing the pnp method:
Here is explained in detail the code for the real time application:
Read 3D textured object model and object mesh.
In order to load the textured model I implemented the class Model which has the function load() that opens a YAML file and take the stored 3D points with its corresponding descriptors. You can find an example of a 3D textured model in samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/cookies_ORB.yml.
In the main program the model is loaded as follows:
In order to read the model mesh I implemented a class Mesh which has a function load() that opens a \(*\).ply file and store the 3D points of the object and also the composed triangles. You can find an example of a model mesh in samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.ply.
In the main program the mesh is loaded as follows:
You can also load different model and mesh:
Take input from Camera or Video
To detect is necessary capture video. It's done loading a recorded video by passing the absolute path where it is located in your machine. In order to test the application you can find a recorded video in samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.mp4.
Then the algorithm is computed frame per frame:
You can also load different recorded video:
Extract ORB features and descriptors from the scene
The next step is to detect the scene features and extract it descriptors. For this task I implemented a class RobustMatcher which has a function for keypoints detection and features extraction. You can find it in samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/src/RobusMatcher.cpp. In your RobusMatch object you can use any of the 2D features detectors of OpenCV. In this case I used cv::ORB features because is based on cv::FAST to detect the keypoints and cv::xfeatures2d::BriefDescriptorExtractor to extract the descriptors which means that is fast and robust to rotations. You can find more detailed information about ORB in the documentation.
The following code is how to instantiate and set the features detector and the descriptors extractor:
The features and descriptors will be computed by the RobustMatcher inside the matching function.
Match scene descriptors with model descriptors using Flann matcher
It is the first step in our detection algorithm. The main idea is to match the scene descriptors with our model descriptors in order to know the 3D coordinates of the found features into the current scene.
Firstly, we have to set which matcher we want to use. In this case is used cv::FlannBasedMatcher matcher which in terms of computational cost is faster than the cv::BFMatcher matcher as we increase the trained collection of features. Then, for FlannBased matcher the index created is Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search due to ORB descriptors are binary.
You can tune the LSH and search parameters to improve the matching efficiency:
Secondly, we have to call the matcher by using robustMatch() or fastRobustMatch() function. The difference of using this two functions is its computational cost. The first method is slower but more robust at filtering good matches because uses two ratio test and a symmetry test. In contrast, the second method is faster but less robust because only applies a single ratio test to the matches.
The following code is to get the model 3D points and its descriptors and then call the matcher in the main program:
The following code corresponds to the robustMatch() function which belongs to the RobustMatcher class. This function uses the given image to detect the keypoints and extract the descriptors, match using two Nearest Neighbour the extracted descriptors with the given model descriptors and vice versa. Then, a ratio test is applied to the two direction matches in order to remove these matches which its distance ratio between the first and second best match is larger than a given threshold. Finally, a symmetry test is applied in order the remove non symmetrical matches.
After the matches filtering we have to subtract the 2D and 3D correspondences from the found scene keypoints and our 3D model using the obtained DMatches vector. For more information about cv::DMatch check the documentation.
You can also change the ratio test threshold, the number of keypoints to detect as well as use or not the robust matcher:
Pose estimation using PnP + Ransac
Once with the 2D and 3D correspondences we have to apply a PnP algorithm in order to estimate the camera pose. The reason why we have to use cv::solvePnPRansac instead of cv::solvePnP is due to the fact that after the matching not all the found correspondences are correct and, as like as not, there are false correspondences or also called outliers. The Random Sample Consensus or Ransac is a non-deterministic iterative method which estimate parameters of a mathematical model from observed data producing an approximate result as the number of iterations increase. After appyling Ransac all the outliers will be eliminated to then estimate the camera pose with a certain probability to obtain a good solution.
For the camera pose estimation I have implemented a class PnPProblem. This class has 4 attributes: a given calibration matrix, the rotation matrix, the translation matrix and the rotation-translation matrix. The intrinsic calibration parameters of the camera which you are using to estimate the pose are necessary. In order to obtain the parameters you can check Camera calibration with square chessboard and Camera calibration With OpenCV tutorials.
The following code is how to declare the PnPProblem class in the main program:
The following code is how the PnPProblem class initialises its attributes:
OpenCV provides four PnP methods: ITERATIVE, EPNP, P3P and DLS. Depending on the application type, the estimation method will be different. In the case that we want to make a real time application, the more suitable methods are EPNP and P3P since they are faster than ITERATIVE and DLS at finding an optimal solution. However, EPNP and P3P are not especially robust in front of planar surfaces and sometimes the pose estimation seems to have a mirror effect. Therefore, in this tutorial an ITERATIVE method is used due to the object to be detected has planar surfaces.
The OpenCV RANSAC implementation wants you to provide three parameters: 1) the maximum number of iterations until the algorithm stops, 2) the maximum allowed distance between the observed and computed point projections to consider it an inlier and 3) the confidence to obtain a good result. You can tune these parameters in order to improve your algorithm performance. Increasing the number of iterations will have a more accurate solution, but will take more time to find a solution. Increasing the reprojection error will reduce the computation time, but your solution will be unaccurate. Decreasing the confidence your algorithm will be faster, but the obtained solution will be unaccurate.
The following parameters work for this application:
The following code corresponds to the estimatePoseRANSAC() function which belongs to the PnPProblem class. This function estimates the rotation and translation matrix given a set of 2D/3D correspondences, the desired PnP method to use, the output inliers container and the Ransac parameters:
In the following code are the 3th and 4th steps of the main algorithm. The first, calling the above function and the second taking the output inliers vector from RANSAC to get the 2D scene points for drawing purpose. As seen in the code we must be sure to apply RANSAC if we have matches, in the other case, the function cv::solvePnPRansac crashes due to any OpenCV bug.
Finally, once the camera pose has been estimated we can use the \(R\) and \(t\) in order to compute the 2D projection onto the image of a given 3D point expressed in a world reference frame using the showed formula on Theory.
The following code corresponds to the backproject3DPoint() function which belongs to the PnPProblem class. The function backproject a given 3D point expressed in a world reference frame onto a 2D image:
The above function is used to compute all the 3D points of the object Mesh to show the pose of the object.
You can also change RANSAC parameters and PnP method:
Linear Kalman Filter for bad poses rejection
Is it common in computer vision or robotics fields that after applying detection or tracking techniques, bad results are obtained due to some sensor errors. In order to avoid these bad detections in this tutorial is explained how to implement a Linear Kalman Filter. The Kalman Filter will be applied after detected a given number of inliers.
You can find more information about what Kalman Filter is. In this tutorial it's used the OpenCV implementation of the cv::KalmanFilter based on Linear Kalman Filter for position and orientation tracking to set the dynamics and measurement models.
Firstly, we have to define our state vector which will have 18 states: the positional data (x,y,z) with its first and second derivatives (velocity and acceleration), then rotation is added in form of three euler angles (roll, pitch, jaw) together with their first and second derivatives (angular velocity and acceleration)
\[X = (x,y,z,\dot x,\dot y,\dot z,\ddot x,\ddot y,\ddot z,\psi,\theta,\phi,\dot \psi,\dot \theta,\dot \phi,\ddot \psi,\ddot \theta,\ddot \phi)^T\]
Secondly, we have to define the number of measurements which will be 6: from \(R\) and \(t\) we can extract \((x,y,z)\) and \((\psi,\theta,\phi)\). In addition, we have to define the number of control actions to apply to the system which in this case will be zero. Finally, we have to define the differential time between measurements which in this case is \(1/T\), where T is the frame rate of the video.
The following code corresponds to the Kalman Filter initialisation. Firstly, is set the process noise, the measurement noise and the error covariance matrix. Secondly, are set the transition matrix which is the dynamic model and finally the measurement matrix, which is the measurement model.
You can tune the process and measurement noise to improve the Kalman Filter performance. As the measurement noise is reduced the faster will converge doing the algorithm sensitive in front of bad measurements.
In the following code is the 5th step of the main algorithm. When the obtained number of inliers after Ransac is over the threshold, the measurements matrix is filled and then the Kalman Filter is updated:
The following code corresponds to the fillMeasurements() function which converts the measured Rotation Matrix to Eulers angles and fill the measurements matrix along with the measured translation vector:
The following code corresponds to the updateKalmanFilter() function which update the Kalman Filter and set the estimated Rotation Matrix and translation vector. The estimated Rotation Matrix comes from the estimated Euler angles to Rotation Matrix.
The 6th step is set the estimated rotation-translation matrix:
The last and optional step is draw the found pose. To do it I implemented a function to draw all the mesh 3D points and an extra reference axis:
You can also modify the minimum inliers to update Kalman Filter:
The following videos are the results of pose estimation in real time using the explained detection algorithm using the following parameters:
You can watch the real time pose estimation on the YouTube here.
 1.8.12
1.8.12