Originally, support vector machines (SVM) was a technique for building an optimal binary (2-class) classifier. Later the technique was extended to regression and clustering problems. SVM is a partial case of kernel-based methods. It maps feature vectors into a higher-dimensional space using a kernel function and builds an optimal linear discriminating function in this space or an optimal hyper-plane that fits into the training data. In case of SVM, the kernel is not defined explicitly. Instead, a distance between any 2 points in the hyper-space needs to be defined.
The solution is optimal, which means that the margin between the separating hyper-plane and the nearest feature vectors from both classes (in case of 2-class classifier) is maximal. The feature vectors that are the closest to the hyper-plane are called support vectors, which means that the position of other vectors does not affect the hyper-plane (the decision function).
SVM implementation in OpenCV is based on [LibSVM].
| [Burges98] |
|
| [LibSVM] | (1, 2) C.-C. Chang and C.-J. Lin. LIBSVM: a library for support vector machines, ACM Transactions on Intelligent Systems and Technology, 2:27:1–27:27, 2011. (http://www.csie.ntu.edu.tw/~cjlin/papers/libsvm.pdf) |
The structure represents the logarithmic grid range of statmodel parameters. It is used for optimizing statmodel accuracy by varying model parameters, the accuracy estimate being computed by cross-validation.
Minimum value of the statmodel parameter.
Maximum value of the statmodel parameter.
Logarithmic step for iterating the statmodel parameter.
The grid determines the following iteration sequence of the statmodel parameter values:

where 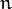 is the maximal index satisfying
is the maximal index satisfying

The grid is logarithmic, so logStep must always be greater then 1.
The constructors.
The full constructor initializes corresponding members. The default constructor creates a dummy grid:
ParamGrid::ParamGrid()
{
minVal = maxVal = 0;
logStep = 1;
}
SVM training parameters.
The structure must be initialized and passed to the training method of SVM.
The constructors
| Parameters: |
|
|---|
The default constructor initialize the structure with following values:
SVMParams::SVMParams() :
svmType(SVM::C_SVC), kernelType(SVM::RBF), degree(0),
gamma(1), coef0(0), C(1), nu(0), p(0), classWeights(0)
{
termCrit = TermCriteria( TermCriteria::MAX_ITER+TermCriteria::EPS, 1000, FLT_EPSILON );
}
A comparison of different kernels on the following 2D test case with four classes. Four C_SVC SVMs have been trained (one against rest) with auto_train. Evaluation on three different kernels (CHI2, INTER, RBF). The color depicts the class with max score. Bright means max-score > 0, dark means max-score < 0.

Support Vector Machines.
Note
Creates empty model
| Parameters: |
|
|---|
Use StatModel::train to train the model, StatModel::train<RTrees>(traindata, params) to create and train the model, StatModel::load<RTrees>(filename) to load the pre-trained model. Since SVM has several parameters, you may want to find the best parameters for your problem. It can be done with SVM::trainAuto.
Trains an SVM with optimal parameters.
| Parameters: |
|
|---|
The method trains the SVM model automatically by choosing the optimal parameters C, gamma, p, nu, coef0, degree from SVM::Params. Parameters are considered optimal when the cross-validation estimate of the test set error is minimal.
If there is no need to optimize a parameter, the corresponding grid step should be set to any value less than or equal to 1. For example, to avoid optimization in gamma, set gammaGrid.step = 0, gammaGrid.minVal, gamma_grid.maxVal as arbitrary numbers. In this case, the value params.gamma is taken for gamma.
And, finally, if the optimization in a parameter is required but the corresponding grid is unknown, you may call the function SVM::getDefaulltGrid(). To generate a grid, for example, for gamma, call SVM::getDefaulltGrid(SVM::GAMMA).
This function works for the classification (params.svmType=SVM::C_SVC or params.svmType=SVM::NU_SVC) as well as for the regression (params.svmType=SVM::EPS_SVR or params.svmType=SVM::NU_SVR). If params.svmType=SVM::ONE_CLASS, no optimization is made and the usual SVM with parameters specified in params is executed.
Generates a grid for SVM parameters.
| Parameters: |
|
|---|
The function generates a grid for the specified parameter of the SVM algorithm. The grid may be passed to the function SVM::trainAuto().
Returns the current SVM parameters.
This function may be used to get the optimal parameters obtained while automatically training SVM::trainAuto.
Retrieves all the support vectors
The method returns all the support vector as floating-point matrix, where support vectors are stored as matrix rows.
Retrieves the decision function
| Parameters: |
|
|---|
The method returns rho parameter of the decision function, a scalar subtracted from the weighted sum of kernel responses.
StatModel::predict(samples, results, flags) should be used. Pass flags=StatModel::RAW_OUTPUT to get the raw response from SVM (in the case of regression, 1-class or 2-class classification problem).
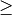 2), allows imperfect separation of classes with penalty multiplier
2), allows imperfect separation of classes with penalty multiplier 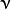 -Support Vector Classification.
-Support Vector Classification. 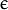 -Support Vector Regression. The distance between feature vectors from the training set and the fitting hyper-plane must be less than
-Support Vector Regression. The distance between feature vectors from the training set and the fitting hyper-plane must be less than 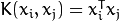 .
.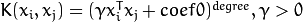 .
.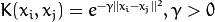 .
.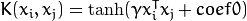 .
.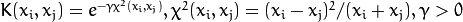 .
.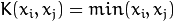 .
.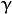 of a kernel function (POLY / RBF / SIGMOID / CHI2).
of a kernel function (POLY / RBF / SIGMOID / CHI2).