Boosting¶
A common machine learning task is supervised learning. In supervised learning, the goal is to learn the functional relationship
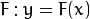 between the input
between the input
 and the output
and the output
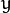 . Predicting the qualitative output is called classification, while predicting the quantitative output is called regression.
. Predicting the qualitative output is called classification, while predicting the quantitative output is called regression.
Boosting is a powerful learning concept that provides a solution to the supervised classification learning task. It combines the performance of many “weak” classifiers to produce a powerful committee [HTF01]. A weak classifier is only required to be better than chance, and thus can be very simple and computationally inexpensive. However, many of them smartly combine results to a strong classifier that often outperforms most “monolithic” strong classifiers such as SVMs and Neural Networks.
Decision trees are the most popular weak classifiers used in boosting schemes. Often the simplest decision trees with only a single split node per tree (called stumps ) are sufficient.
The boosted model is based on
 training examples
training examples
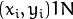 with
with
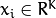 and
and
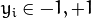 .
.
 is a
is a
 -component vector. Each component encodes a feature relevant to the learning task at hand. The desired two-class output is encoded as -1 and +1.
-component vector. Each component encodes a feature relevant to the learning task at hand. The desired two-class output is encoded as -1 and +1.
Different variants of boosting are known as Discrete Adaboost, Real AdaBoost, LogitBoost, and Gentle AdaBoost [FHT98]. All of them are very similar in their overall structure. Therefore, this chapter focuses only on the standard two-class Discrete AdaBoost algorithm, outlined below. Initially the same weight is assigned to each sample (step 2). Then, a weak classifier
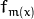 is trained on the weighted training data (step 3a). Its weighted training error and scaling factor
is trained on the weighted training data (step 3a). Its weighted training error and scaling factor
 is computed (step 3b). The weights are increased for training samples that have been misclassified (step 3c). All weights are then normalized, and the process of finding the next weak classifier continues for another
is computed (step 3b). The weights are increased for training samples that have been misclassified (step 3c). All weights are then normalized, and the process of finding the next weak classifier continues for another
 -1 times. The final classifier
-1 times. The final classifier
 is the sign of the weighted sum over the individual weak classifiers (step 4).
is the sign of the weighted sum over the individual weak classifiers (step 4).
Two-class Discrete AdaBoost Algorithm
Set
examples
with
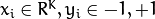 .
.Assign weights as
 .
.Repeat for
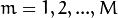 :
:3.1. Fit the classifier
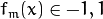 , using weights
, using weights  on the training data.
on the training data.3.2. Compute
![err_m = E_w [1_{(y \neq f_m(x))}], c_m = log((1 - err_m)/err_m)](../../../_images/math/a514d7f1ad86153084f97feb69a8bc38999072d1.png) .
.3.3. Set
![w_i \Leftarrow w_i exp[c_m 1_{(y_i \neq f_m(x_i))}], i = 1,2,...,N,](../../../_images/math/623832767d93c023f95b4f40ae733380c43c9485.png) and renormalize so that
and renormalize so that 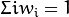 .
.Classify new samples x using the formula:
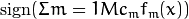 .
.
Note
Similar to the classical boosting methods, the current implementation supports two-class classifiers only. For M > 2 classes, there is the AdaBoost.MH algorithm (described in [FHT98]) that reduces the problem to the two-class problem, yet with a much larger training set.
To reduce computation time for boosted models without substantially losing accuracy, the influence trimming technique can be employed. As the training algorithm proceeds and the number of trees in the ensemble is increased, a larger number of the training samples are classified correctly and with increasing confidence, thereby those samples receive smaller weights on the subsequent iterations. Examples with a very low relative weight have a small impact on the weak classifier training. Thus, such examples may be excluded during the weak classifier training without having much effect on the induced classifier. This process is controlled with the weight_trim_rate parameter. Only examples with the summary fraction weight_trim_rate of the total weight mass are used in the weak classifier training. Note that the weights for all training examples are recomputed at each training iteration. Examples deleted at a particular iteration may be used again for learning some of the weak classifiers further [FHT98].
| [HTF01] | Hastie, T., Tibshirani, R., Friedman, J. H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer Series in Statistics. 2001. |
| [FHT98] | (1, 2, 3) Friedman, J. H., Hastie, T. and Tibshirani, R. Additive Logistic Regression: a Statistical View of Boosting. Technical Report, Dept. of Statistics*, Stanford University, 1998. |
Boost::Params¶
- struct Boost::Params : public DTree::Params¶
Boosting training parameters.
The structure is derived from DTrees::Params but not all of the decision tree parameters are supported. In particular, cross-validation is not supported.
All parameters are public. You can initialize them by a constructor and then override some of them directly if you want.
Boost::Params::Params¶
The constructors.
- C++: Boost::Params::Params()¶
- C++: Boost::Params::Params(int boostType, int weakCount, double weightTrimRate, int maxDepth, bool useSurrogates, const Mat& priors)¶
Parameters: - boost_type –
Type of the boosting algorithm. Possible values are:
- Boost::DISCRETE Discrete AdaBoost.
- Boost::REAL Real AdaBoost. It is a technique that utilizes confidence-rated predictions and works well with categorical data.
- Boost::LOGIT LogitBoost. It can produce good regression fits.
- Boost::GENTLE Gentle AdaBoost. It puts less weight on outlier data points and for that reason is often good with regression data.
Gentle AdaBoost and Real AdaBoost are often the preferable choices.
- weak_count – The number of weak classifiers.
- weight_trim_rate – A threshold between 0 and 1 used to save computational time. Samples with summary weight
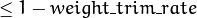 do not participate in the next iteration of training. Set this parameter to 0 to turn off this functionality.
do not participate in the next iteration of training. Set this parameter to 0 to turn off this functionality.
- boost_type –
See DTrees::Params for description of other parameters.
Default parameters are:
Boost::Params::Params()
{
boostType = Boost::REAL;
weakCount = 100;
weightTrimRate = 0.95;
CVFolds = 0;
maxDepth = 1;
}
Boost::create¶
Creates the empty model
- C++: Ptr<Boost> Boost::create(const Params& params=Params())¶
Use StatModel::train to train the model, StatModel::train<Boost>(traindata, params) to create and train the model, StatModel::load<Boost>(filename) to load the pre-trained model.
Boost::getBParams¶
Returns the boosting parameters
- C++: Params Boost::getBParams() const¶
The method returns the training parameters.
Boost::setBParams¶
Sets the boosting parameters
- C++: void Boost::setBParams(const Params& p)¶
Parameters: - p – Training parameters of type Boost::Params.
The method sets the training parameters.
Prediction with Boost¶
StatModel::predict(samples, results, flags) should be used. Pass flags=StatModel::RAW_OUTPUT to get the raw sum from Boost classifier.
Help and Feedback
You did not find what you were looking for?- Ask a question on the Q&A forum.
- If you think something is missing or wrong in the documentation, please file a bug report.