Data Structures¶
gpu::PtrStepSz¶
-
class
gpu::PtrStepSz¶
Lightweight class encapsulating pitched memory on a GPU and passed to nvcc-compiled code (CUDA kernels). Typically, it is used internally by OpenCV and by users who write device code. You can call its members from both host and device code.
template <typename T> struct PtrStepSz
{
int cols;
int rows;
T* data;
size_t step;
PtrStepSz() : cols(0), rows(0), data(0), step(0){};
PtrStepSz(int rows, int cols, T *data, size_t step);
template <typename U>
explicit PtrStepSz(const PtrStepSz<U>& d);
typedef T elem_type;
enum { elem_size = sizeof(elem_type) };
__CV_GPU_HOST_DEVICE__ size_t elemSize() const;
/* returns pointer to the beginning of the given image row */
__CV_GPU_HOST_DEVICE__ T* ptr(int y = 0);
__CV_GPU_HOST_DEVICE__ const T* ptr(int y = 0) const;
};
typedef PtrStepSz<unsigned char> PtrStepSzb;
typedef PtrStepSz<float> PtrStepSzf;
typedef PtrStepSz<int> PtrStepSzi;
gpu::PtrStep¶
-
class
gpu::PtrStep¶
Structure similar to gpu::PtrStepSz but containing only a pointer and row step. Width and height fields are excluded due to performance reasons. The structure is intended for internal use or for users who write device code.
template<typename T> struct PtrStep
{
T* data;
size_t step;
PtrStep();
PtrStep(const PtrStepSz<T>& mem);
typedef T elem_type;
enum { elem_size = sizeof(elem_type) };
__CV_GPU_HOST_DEVICE__ size_t elemSize() const;
__CV_GPU_HOST_DEVICE__ T* ptr(int y = 0);
__CV_GPU_HOST_DEVICE__ const T* ptr(int y = 0) const;
};
typedef PtrStep<unsigned char> PtrStep;
typedef PtrStep<float> PtrStepf;
typedef PtrStep<int> PtrStepi;
gpu::GpuMat¶
-
class
gpu::GpuMat¶
Base storage class for GPU memory with reference counting. Its interface matches the Mat interface with the following limitations:
- no arbitrary dimensions support (only 2D)
- no functions that return references to their data (because references on GPU are not valid for CPU)
- no expression templates technique support
Beware that the latter limitation may lead to overloaded matrix operators that cause memory allocations. The GpuMat class is convertible to gpu::PtrStepSz and gpu::PtrStep so it can be passed directly to the kernel.
Note
In contrast with Mat, in most cases GpuMat::isContinuous() == false . This means that rows are aligned to a size depending on the hardware. Single-row GpuMat is always a continuous matrix.
class CV_EXPORTS GpuMat
{
public:
//! default constructor
GpuMat();
GpuMat(int rows, int cols, int type);
GpuMat(Size size, int type);
.....
//! builds GpuMat from Mat. Blocks uploading to device.
explicit GpuMat (const Mat& m);
//! returns lightweight PtrStepSz structure for passing
//to nvcc-compiled code. Contains size, data ptr and step.
template <class T> operator PtrStepSz<T>() const;
template <class T> operator PtrStep<T>() const;
//! blocks uploading data to GpuMat.
void upload(const cv::Mat& m);
void upload(const CudaMem& m, Stream& stream);
//! downloads data from device to host memory. Blocking calls.
void download(cv::Mat& m) const;
//! download async
void download(CudaMem& m, Stream& stream) const;
};
Note
You are not recommended to leave static or global GpuMat variables allocated, that is, to rely on its destructor. The destruction order of such variables and CUDA context is undefined. GPU memory release function returns error if the CUDA context has been destroyed before.
See also
gpu::createContinuous¶
Creates a continuous matrix in the GPU memory.
-
C++:
gpu::createContinuous(int rows, int cols, int type, GpuMat& m)¶
-
C++:
gpu::createContinuous(int rows, int cols, int type)¶
-
C++:
gpu::createContinuous(Size size, int type, GpuMat& m)¶
-
C++:
gpu::createContinuous(Size size, int type)¶ Parameters: - rows – Row count.
- cols – Column count.
- type – Type of the matrix.
- m – Destination matrix. This parameter changes only if it has a proper type and area (
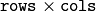 ).
).
Matrix is called continuous if its elements are stored continuously, that is, without gaps at the end of each row.
gpu::ensureSizeIsEnough¶
Ensures that the size of a matrix is big enough and the matrix has a proper type.
-
C++:
gpu::ensureSizeIsEnough(int rows, int cols, int type, GpuMat& m)¶
-
C++:
gpu::ensureSizeIsEnough(Size size, int type, GpuMat& m)¶ Parameters: - rows – Minimum desired number of rows.
- cols – Minimum desired number of columns.
- size – Rows and columns passed as a structure.
- type – Desired matrix type.
- m – Destination matrix.
The function does not reallocate memory if the matrix has proper attributes already.
gpu::registerPageLocked¶
Page-locks the memory of matrix and maps it for the device(s).
-
C++:
gpu::registerPageLocked(Mat& m)¶ Parameters: - m – Input matrix.
gpu::unregisterPageLocked¶
Unmaps the memory of matrix and makes it pageable again.
-
C++:
gpu::unregisterPageLocked(Mat& m)¶ Parameters: - m – Input matrix.
gpu::CudaMem¶
-
class
gpu::CudaMem¶
Class with reference counting wrapping special memory type allocation functions from CUDA. Its interface is also
Mat()-like but with additional memory type parameters.
- ALLOC_PAGE_LOCKED sets a page locked memory type used commonly for fast and asynchronous uploading/downloading data from/to GPU.
- ALLOC_ZEROCOPY specifies a zero copy memory allocation that enables mapping the host memory to GPU address space, if supported.
- ALLOC_WRITE_COMBINED sets the write combined buffer that is not cached by CPU. Such buffers are used to supply GPU with data when GPU only reads it. The advantage is a better CPU cache utilization.
Note
Allocation size of such memory types is usually limited. For more details, see CUDA 2.2 Pinned Memory APIs document or CUDA C Programming Guide.
class CV_EXPORTS CudaMem
{
public:
enum { ALLOC_PAGE_LOCKED = 1, ALLOC_ZEROCOPY = 2,
ALLOC_WRITE_COMBINED = 4 };
CudaMem(Size size, int type, int alloc_type = ALLOC_PAGE_LOCKED);
//! creates from cv::Mat with coping data
explicit CudaMem(const Mat& m, int alloc_type = ALLOC_PAGE_LOCKED);
......
void create(Size size, int type, int alloc_type = ALLOC_PAGE_LOCKED);
//! returns matrix header with disabled ref. counting for CudaMem data.
Mat createMatHeader() const;
operator Mat() const;
//! maps host memory into device address space
GpuMat createGpuMatHeader() const;
operator GpuMat() const;
//if host memory can be mapped to gpu address space;
static bool canMapHostMemory();
int alloc_type;
};
gpu::CudaMem::createMatHeader¶
Creates a header without reference counting to gpu::CudaMem data.
-
C++:
gpu::CudaMem::createMatHeader()const¶
gpu::CudaMem::createGpuMatHeader¶
Maps CPU memory to GPU address space and creates the gpu::GpuMat header without reference counting for it.
-
C++:
gpu::CudaMem::createGpuMatHeader()const¶
This can be done only if memory was allocated with the ALLOC_ZEROCOPY flag and if it is supported by the hardware. Laptops often share video and CPU memory, so address spaces can be mapped, which eliminates an extra copy.
gpu::CudaMem::canMapHostMemory¶
Returns true if the current hardware supports address space mapping and ALLOC_ZEROCOPY memory allocation.
-
C++:
gpu::CudaMem::canMapHostMemory()¶
gpu::Stream¶
-
class
gpu::Stream¶
This class encapsulates a queue of asynchronous calls. Some functions have overloads with the additional gpu::Stream parameter. The overloads do initialization work (allocate output buffers, upload constants, and so on), start the GPU kernel, and return before results are ready. You can check whether all operations are complete via gpu::Stream::queryIfComplete(). You can asynchronously upload/download data from/to page-locked buffers, using the gpu::CudaMem or Mat header that points to a region of gpu::CudaMem.
Note
Currently, you may face problems if an operation is enqueued twice with different data. Some functions use the constant GPU memory, and next call may update the memory before the previous one has been finished. But calling different operations asynchronously is safe because each operation has its own constant buffer. Memory copy/upload/download/set operations to the buffers you hold are also safe.
class CV_EXPORTS Stream
{
public:
Stream();
~Stream();
Stream(const Stream&);
Stream& operator=(const Stream&);
bool queryIfComplete();
void waitForCompletion();
void enqueueDownload(const GpuMat& src, CudaMem& dst);
void enqueueDownload(const GpuMat& src, Mat& dst);
void enqueueUpload(const CudaMem& src, GpuMat& dst);
void enqueueUpload(const Mat& src, GpuMat& dst);
void enqueueCopy(const GpuMat& src, GpuMat& dst);
void enqueueMemSet(const GpuMat& src, Scalar val);
void enqueueMemSet(const GpuMat& src, Scalar val, const GpuMat& mask);
void enqueueConvert(const GpuMat& src, GpuMat& dst, int type,
double a = 1, double b = 0);
typedef void (*StreamCallback)(Stream& stream, int status, void* userData);
void enqueueHostCallback(StreamCallback callback, void* userData);
};
gpu::Stream::queryIfComplete¶
Returns true if the current stream queue is finished. Otherwise, it returns false.
-
C++:
gpu::Stream::queryIfComplete()¶
gpu::Stream::waitForCompletion¶
Blocks the current CPU thread until all operations in the stream are complete.
-
C++:
gpu::Stream::waitForCompletion()¶
gpu::Stream::enqueueDownload¶
Copies data from device to host.
-
C++:
gpu::Stream::enqueueDownload(const GpuMat& src, CudaMem& dst)¶
-
C++:
gpu::Stream::enqueueDownload(const GpuMat& src, Mat& dst)¶
Note
cv::Mat must point to page locked memory (i.e. to CudaMem data or to its subMat) or must be registered with gpu::registerPageLocked() .
gpu::Stream::enqueueUpload¶
Copies data from host to device.
-
C++:
gpu::Stream::enqueueUpload(const CudaMem& src, GpuMat& dst)¶
-
C++:
gpu::Stream::enqueueUpload(const Mat& src, GpuMat& dst)¶
Note
cv::Mat must point to page locked memory (i.e. to CudaMem data or to its subMat) or must be registered with gpu::registerPageLocked() .
gpu::Stream::enqueueCopy¶
Copies data from device to device.
-
C++:
gpu::Stream::enqueueCopy(const GpuMat& src, GpuMat& dst)¶
gpu::Stream::enqueueMemSet¶
Initializes or sets device memory to a value.
-
C++:
gpu::Stream::enqueueMemSet(GpuMat& src, Scalar val)¶
-
C++:
gpu::Stream::enqueueMemSet(GpuMat& src, Scalar val, const GpuMat& mask)¶
gpu::Stream::enqueueConvert¶
Converts matrix type, ex from float to uchar depending on type.
-
C++:
gpu::Stream::enqueueConvert(const GpuMat& src, GpuMat& dst, int dtype, double a=1, double b=0 )¶
gpu::Stream::enqueueHostCallback¶
Adds a callback to be called on the host after all currently enqueued items in the stream have completed.
-
C++:
gpu::Stream::enqueueHostCallback(StreamCallback callback, void* userData)¶
Note
Callbacks must not make any CUDA API calls. Callbacks must not perform any synchronization that may depend on outstanding device work or other callbacks that are not mandated to run earlier. Callbacks without a mandated order (in independent streams) execute in undefined order and may be serialized.
gpu::StreamAccessor¶
-
struct
gpu::StreamAccessor¶
Class that enables getting cudaStream_t from gpu::Stream and is declared in stream_accessor.hpp because it is the only public header that depends on the CUDA Runtime API. Including it brings a dependency to your code.
struct StreamAccessor
{
CV_EXPORTS static cudaStream_t getStream(const Stream& stream);
};
Help and Feedback
You did not find what you were looking for?- Ask a question on the Q&A forum.
- If you think something is missing or wrong in the documentation, please file a bug report.
![]()
Table Of Contents
- Data Structures
- gpu::PtrStepSz
- gpu::PtrStep
- gpu::GpuMat
- gpu::createContinuous
- gpu::ensureSizeIsEnough
- gpu::registerPageLocked
- gpu::unregisterPageLocked
- gpu::CudaMem
- gpu::CudaMem::createMatHeader
- gpu::CudaMem::createGpuMatHeader
- gpu::CudaMem::canMapHostMemory
- gpu::Stream
- gpu::Stream::queryIfComplete
- gpu::Stream::waitForCompletion
- gpu::Stream::enqueueDownload
- gpu::Stream::enqueueUpload
- gpu::Stream::enqueueCopy
- gpu::Stream::enqueueMemSet
- gpu::Stream::enqueueConvert
- gpu::Stream::enqueueHostCallback
- gpu::StreamAccessor